This is the multi-page printable view of this section. Click here to print.
Stateful Applications
- 1: StatefulSet Basics
- 2: Example: Deploying WordPress and MySQL with Persistent Volumes
- 3: Example: Deploying Cassandra with a StatefulSet
- 4: Running ZooKeeper, A Distributed System Coordinator
1 - StatefulSet Basics
This tutorial provides an introduction to managing applications with StatefulSets. It demonstrates how to create, delete, scale, and update the Pods of StatefulSets.
Before you begin
Before you begin this tutorial, you should familiarize yourself with the following Kubernetes concepts:
- Pods
- Cluster DNS
- Headless Services
- PersistentVolumes
- PersistentVolume Provisioning
- StatefulSets
- The kubectl command line tool
Objectives
StatefulSets are intended to be used with stateful applications and distributed systems. However, the administration of stateful applications and distributed systems on Kubernetes is a broad, complex topic. In order to demonstrate the basic features of a StatefulSet, and not to conflate the former topic with the latter, you will deploy a simple web application using a StatefulSet.
After this tutorial, you will be familiar with the following.
- How to create a StatefulSet
- How a StatefulSet manages its Pods
- How to delete a StatefulSet
- How to scale a StatefulSet
- How to update a StatefulSet's Pods
Creating a StatefulSet
Begin by creating a StatefulSet using the example below. It is similar to the
example presented in the
StatefulSets concept.
It creates a headless Service,
nginx, to publish the IP addresses of Pods in the StatefulSet, web.

apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
Download the example above, and save it to a file named web.yaml
You will need to use two terminal windows. In the first terminal, use
kubectl get to watch the creation
of the StatefulSet's Pods.
kubectl get pods -w -l app=nginx
In the second terminal, use
kubectl apply to create the
headless Service and StatefulSet defined in web.yaml.
kubectl apply -f web.yaml
service/nginx created
statefulset.apps/web created
The command above creates two Pods, each running an
NGINX webserver. Get the nginx Service...
kubectl get service nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP None <none> 80/TCP 12s
...then get the web StatefulSet, to verify that both were created successfully:
kubectl get statefulset web
NAME DESIRED CURRENT AGE
web 2 1 20s
Ordered Pod Creation
For a StatefulSet with n replicas, when Pods are being deployed, they are
created sequentially, ordered from {0..n-1}. Examine the output of the
kubectl get command in the first terminal. Eventually, the output will
look like the example below.
kubectl get pods -w -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 19s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 18s
Notice that the web-1 Pod is not launched until the web-0 Pod is
Running (see Pod Phase)
and Ready (see type in Pod Conditions).
Pods in a StatefulSet
Pods in a StatefulSet have a unique ordinal index and a stable network identity.
Examining the Pod's Ordinal Index
Get the StatefulSet's Pods:
kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 1m
web-1 1/1 Running 0 1m
As mentioned in the StatefulSets
concept, the Pods in a StatefulSet have a sticky, unique identity. This identity
is based on a unique ordinal index that is assigned to each Pod by the
StatefulSet controller.
The Pods' names take the form <statefulset name>-<ordinal index>.
Since the web StatefulSet has two replicas, it creates two Pods, web-0 and web-1.
Using Stable Network Identities
Each Pod has a stable hostname based on its ordinal index. Use
kubectl exec to execute the
hostname command in each Pod:
for i in 0 1; do kubectl exec "web-$i" -- sh -c 'hostname'; done
web-0
web-1
Use kubectl run to execute
a container that provides the nslookup command from the dnsutils package.
Using nslookup on the Pods' hostnames, you can examine their in-cluster DNS
addresses:
kubectl run -i --tty --image busybox:1.28 dns-test --restart=Never --rm
which starts a new shell. In that new shell, run:
# Run this in the dns-test container shell
nslookup web-0.nginx
The output is similar to:
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx
Address 1: 10.244.1.6
nslookup web-1.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-1.nginx
Address 1: 10.244.2.6
(and now exit the container shell: exit)
The CNAME of the headless service points to SRV records (one for each Pod that is Running and Ready). The SRV records point to A record entries that contain the Pods' IP addresses.
In one terminal, watch the StatefulSet's Pods:
kubectl get pod -w -l app=nginx
In a second terminal, use
kubectl delete to delete all
the Pods in the StatefulSet:
kubectl delete pod -l app=nginx
pod "web-0" deleted
pod "web-1" deleted
Wait for the StatefulSet to restart them, and for both Pods to transition to Running and Ready:
kubectl get pod -w -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 0/1 ContainerCreating 0 0s
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 2s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 34s
Use kubectl exec and kubectl run to view the Pods' hostnames and in-cluster
DNS entries. First, view the Pods' hostnames:
for i in 0 1; do kubectl exec web-$i -- sh -c 'hostname'; done
web-0
web-1
then, run:
kubectl run -i --tty --image busybox:1.28 dns-test --restart=Never --rm /bin/sh
which starts a new shell.
In that new shell, run:
# Run this in the dns-test container shell
nslookup web-0.nginx
The output is similar to:
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-0.nginx
Address 1: 10.244.1.7
nslookup web-1.nginx
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
Name: web-1.nginx
Address 1: 10.244.2.8
(and now exit the container shell: exit)
The Pods' ordinals, hostnames, SRV records, and A record names have not changed, but the IP addresses associated with the Pods may have changed. In the cluster used for this tutorial, they have. This is why it is important not to configure other applications to connect to Pods in a StatefulSet by IP address.
If you need to find and connect to the active members of a StatefulSet, you
should query the CNAME of the headless Service
(nginx.default.svc.cluster.local). The SRV records associated with the
CNAME will contain only the Pods in the StatefulSet that are Running and
Ready.
If your application already implements connection logic that tests for
liveness and readiness, you can use the SRV records of the Pods (
web-0.nginx.default.svc.cluster.local,
web-1.nginx.default.svc.cluster.local), as they are stable, and your
application will be able to discover the Pods' addresses when they transition
to Running and Ready.
Writing to Stable Storage
Get the PersistentVolumeClaims for web-0 and web-1:
kubectl get pvc -l app=nginx
The output is similar to:
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
www-web-0 Bound pvc-15c268c7-b507-11e6-932f-42010a800002 1Gi RWO 48s
www-web-1 Bound pvc-15c79307-b507-11e6-932f-42010a800002 1Gi RWO 48s
The StatefulSet controller created two PersistentVolumeClaims that are bound to two PersistentVolumes.
As the cluster used in this tutorial is configured to dynamically provision PersistentVolumes, the PersistentVolumes were created and bound automatically.
The NGINX webserver, by default, serves an index file from
/usr/share/nginx/html/index.html. The volumeMounts field in the
StatefulSet's spec ensures that the /usr/share/nginx/html directory is
backed by a PersistentVolume.
Write the Pods' hostnames to their index.html files and verify that the NGINX
webservers serve the hostnames:
for i in 0 1; do kubectl exec "web-$i" -- sh -c 'echo "$(hostname)" > /usr/share/nginx/html/index.html'; done
for i in 0 1; do kubectl exec -i -t "web-$i" -- curl http://localhost/; done
web-0
web-1
If you instead see 403 Forbidden responses for the above curl command,
you will need to fix the permissions of the directory mounted by the volumeMounts
(due to a bug when using hostPath volumes),
by running:
for i in 0 1; do kubectl exec web-$i -- chmod 755 /usr/share/nginx/html; done
before retrying the curl command above.
In one terminal, watch the StatefulSet's Pods:
kubectl get pod -w -l app=nginx
In a second terminal, delete all of the StatefulSet's Pods:
kubectl delete pod -l app=nginx
pod "web-0" deleted
pod "web-1" deleted
Examine the output of the kubectl get command in the first terminal, and wait
for all of the Pods to transition to Running and Ready.
kubectl get pod -w -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 0/1 ContainerCreating 0 0s
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 2s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 34s
Verify the web servers continue to serve their hostnames:
for i in 0 1; do kubectl exec -i -t "web-$i" -- curl http://localhost/; done
web-0
web-1
Even though web-0 and web-1 were rescheduled, they continue to serve their
hostnames because the PersistentVolumes associated with their
PersistentVolumeClaims are remounted to their volumeMounts. No matter what
node web-0and web-1 are scheduled on, their PersistentVolumes will be
mounted to the appropriate mount points.
Scaling a StatefulSet
Scaling a StatefulSet refers to increasing or decreasing the number of replicas.
This is accomplished by updating the replicas field. You can use either
kubectl scale or
kubectl patch to scale a StatefulSet.
Scaling Up
In one terminal window, watch the Pods in the StatefulSet:
kubectl get pods -w -l app=nginx
In another terminal window, use kubectl scale to scale the number of replicas
to 5:
kubectl scale sts web --replicas=5
statefulset.apps/web scaled
Examine the output of the kubectl get command in the first terminal, and wait
for the three additional Pods to transition to Running and Ready.
kubectl get pods -w -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 2h
web-1 1/1 Running 0 2h
NAME READY STATUS RESTARTS AGE
web-2 0/1 Pending 0 0s
web-2 0/1 Pending 0 0s
web-2 0/1 ContainerCreating 0 0s
web-2 1/1 Running 0 19s
web-3 0/1 Pending 0 0s
web-3 0/1 Pending 0 0s
web-3 0/1 ContainerCreating 0 0s
web-3 1/1 Running 0 18s
web-4 0/1 Pending 0 0s
web-4 0/1 Pending 0 0s
web-4 0/1 ContainerCreating 0 0s
web-4 1/1 Running 0 19s
The StatefulSet controller scaled the number of replicas. As with StatefulSet creation, the StatefulSet controller created each Pod sequentially with respect to its ordinal index, and it waited for each Pod's predecessor to be Running and Ready before launching the subsequent Pod.
Scaling Down
In one terminal, watch the StatefulSet's Pods:
kubectl get pods -w -l app=nginx
In another terminal, use kubectl patch to scale the StatefulSet back down to
three replicas:
kubectl patch sts web -p '{"spec":{"replicas":3}}'
statefulset.apps/web patched
Wait for web-4 and web-3 to transition to Terminating.
kubectl get pods -w -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 3h
web-1 1/1 Running 0 3h
web-2 1/1 Running 0 55s
web-3 1/1 Running 0 36s
web-4 0/1 ContainerCreating 0 18s
NAME READY STATUS RESTARTS AGE
web-4 1/1 Running 0 19s
web-4 1/1 Terminating 0 24s
web-4 1/1 Terminating 0 24s
web-3 1/1 Terminating 0 42s
web-3 1/1 Terminating 0 42s
Ordered Pod Termination
The controller deleted one Pod at a time, in reverse order with respect to its ordinal index, and it waited for each to be completely shutdown before deleting the next.
Get the StatefulSet's PersistentVolumeClaims:
kubectl get pvc -l app=nginx
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
www-web-0 Bound pvc-15c268c7-b507-11e6-932f-42010a800002 1Gi RWO 13h
www-web-1 Bound pvc-15c79307-b507-11e6-932f-42010a800002 1Gi RWO 13h
www-web-2 Bound pvc-e1125b27-b508-11e6-932f-42010a800002 1Gi RWO 13h
www-web-3 Bound pvc-e1176df6-b508-11e6-932f-42010a800002 1Gi RWO 13h
www-web-4 Bound pvc-e11bb5f8-b508-11e6-932f-42010a800002 1Gi RWO 13h
There are still five PersistentVolumeClaims and five PersistentVolumes. When exploring a Pod's stable storage, we saw that the PersistentVolumes mounted to the Pods of a StatefulSet are not deleted when the StatefulSet's Pods are deleted. This is still true when Pod deletion is caused by scaling the StatefulSet down.
Updating StatefulSets
In Kubernetes 1.7 and later, the StatefulSet controller supports automated updates. The
strategy used is determined by the spec.updateStrategy field of the
StatefulSet API Object. This feature can be used to upgrade the container
images, resource requests and/or limits, labels, and annotations of the Pods in a
StatefulSet. There are two valid update strategies, RollingUpdate and
OnDelete.
RollingUpdate update strategy is the default for StatefulSets.
Rolling Update
The RollingUpdate update strategy will update all Pods in a StatefulSet, in
reverse ordinal order, while respecting the StatefulSet guarantees.
Patch the web StatefulSet to apply the RollingUpdate update strategy:
kubectl patch statefulset web -p '{"spec":{"updateStrategy":{"type":"RollingUpdate"}}}'
statefulset.apps/web patched
In one terminal window, patch the web StatefulSet to change the container
image again:
kubectl patch statefulset web --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"gcr.io/google_containers/nginx-slim:0.8"}]'
statefulset.apps/web patched
In another terminal, watch the Pods in the StatefulSet:
kubectl get pod -l app=nginx -w
The output is similar to:
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 7m
web-1 1/1 Running 0 7m
web-2 1/1 Running 0 8m
web-2 1/1 Terminating 0 8m
web-2 1/1 Terminating 0 8m
web-2 0/1 Terminating 0 8m
web-2 0/1 Terminating 0 8m
web-2 0/1 Terminating 0 8m
web-2 0/1 Terminating 0 8m
web-2 0/1 Pending 0 0s
web-2 0/1 Pending 0 0s
web-2 0/1 ContainerCreating 0 0s
web-2 1/1 Running 0 19s
web-1 1/1 Terminating 0 8m
web-1 0/1 Terminating 0 8m
web-1 0/1 Terminating 0 8m
web-1 0/1 Terminating 0 8m
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 6s
web-0 1/1 Terminating 0 7m
web-0 1/1 Terminating 0 7m
web-0 0/1 Terminating 0 7m
web-0 0/1 Terminating 0 7m
web-0 0/1 Terminating 0 7m
web-0 0/1 Terminating 0 7m
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 10s
The Pods in the StatefulSet are updated in reverse ordinal order. The StatefulSet controller terminates each Pod, and waits for it to transition to Running and Ready prior to updating the next Pod. Note that, even though the StatefulSet controller will not proceed to update the next Pod until its ordinal successor is Running and Ready, it will restore any Pod that fails during the update to its current version.
Pods that have already received the update will be restored to the updated version, and Pods that have not yet received the update will be restored to the previous version. In this way, the controller attempts to continue to keep the application healthy and the update consistent in the presence of intermittent failures.
Get the Pods to view their container images:
for p in 0 1 2; do kubectl get pod "web-$p" --template '{{range $i, $c := .spec.containers}}{{$c.image}}{{end}}'; echo; done
k8s.gcr.io/nginx-slim:0.8
k8s.gcr.io/nginx-slim:0.8
k8s.gcr.io/nginx-slim:0.8
All the Pods in the StatefulSet are now running the previous container image.
kubectl rollout status sts/<name> to view
the status of a rolling update to a StatefulSet
Staging an Update
You can stage an update to a StatefulSet by using the partition parameter of
the RollingUpdate update strategy. A staged update will keep all of the Pods
in the StatefulSet at the current version while allowing mutations to the
StatefulSet's .spec.template.
Patch the web StatefulSet to add a partition to the updateStrategy field:
kubectl patch statefulset web -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":3}}}}'
statefulset.apps/web patched
Patch the StatefulSet again to change the container's image:
kubectl patch statefulset web --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"k8s.gcr.io/nginx-slim:0.7"}]'
statefulset.apps/web patched
Delete a Pod in the StatefulSet:
kubectl delete pod web-2
pod "web-2" deleted
Wait for the Pod to be Running and Ready.
kubectl get pod -l app=nginx -w
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 4m
web-1 1/1 Running 0 4m
web-2 0/1 ContainerCreating 0 11s
web-2 1/1 Running 0 18s
Get the Pod's container image:
kubectl get pod web-2 --template '{{range $i, $c := .spec.containers}}{{$c.image}}{{end}}'
k8s.gcr.io/nginx-slim:0.8
Notice that, even though the update strategy is RollingUpdate the StatefulSet
restored the Pod with its original container. This is because the
ordinal of the Pod is less than the partition specified by the
updateStrategy.
Rolling Out a Canary
You can roll out a canary to test a modification by decrementing the partition
you specified above.
Patch the StatefulSet to decrement the partition:
kubectl patch statefulset web -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":2}}}}'
statefulset.apps/web patched
Wait for web-2 to be Running and Ready.
kubectl get pod -l app=nginx -w
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 4m
web-1 1/1 Running 0 4m
web-2 0/1 ContainerCreating 0 11s
web-2 1/1 Running 0 18s
Get the Pod's container:
kubectl get pod web-2 --template '{{range $i, $c := .spec.containers}}{{$c.image}}{{end}}'
k8s.gcr.io/nginx-slim:0.7
When you changed the partition, the StatefulSet controller automatically
updated the web-2 Pod because the Pod's ordinal was greater than or equal to
the partition.
Delete the web-1 Pod:
kubectl delete pod web-1
pod "web-1" deleted
Wait for the web-1 Pod to be Running and Ready.
kubectl get pod -l app=nginx -w
The output is similar to:
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 6m
web-1 0/1 Terminating 0 6m
web-2 1/1 Running 0 2m
web-1 0/1 Terminating 0 6m
web-1 0/1 Terminating 0 6m
web-1 0/1 Terminating 0 6m
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 18s
Get the web-1 Pod's container image:
kubectl get pod web-1 --template '{{range $i, $c := .spec.containers}}{{$c.image}}{{end}}'
k8s.gcr.io/nginx-slim:0.8
web-1 was restored to its original configuration because the Pod's ordinal
was less than the partition. When a partition is specified, all Pods with an
ordinal that is greater than or equal to the partition will be updated when the
StatefulSet's .spec.template is updated. If a Pod that has an ordinal less
than the partition is deleted or otherwise terminated, it will be restored to
its original configuration.
Phased Roll Outs
You can perform a phased roll out (e.g. a linear, geometric, or exponential
roll out) using a partitioned rolling update in a similar manner to how you
rolled out a canary. To perform a phased roll out, set
the partition to the ordinal at which you want the controller to pause the
update.
The partition is currently set to 2. Set the partition to 0:
kubectl patch statefulset web -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":0}}}}'
statefulset.apps/web patched
Wait for all of the Pods in the StatefulSet to become Running and Ready.
kubectl get pod -l app=nginx -w
The output is similar to:
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 3m
web-1 0/1 ContainerCreating 0 11s
web-2 1/1 Running 0 2m
web-1 1/1 Running 0 18s
web-0 1/1 Terminating 0 3m
web-0 1/1 Terminating 0 3m
web-0 0/1 Terminating 0 3m
web-0 0/1 Terminating 0 3m
web-0 0/1 Terminating 0 3m
web-0 0/1 Terminating 0 3m
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 3s
Get the container image details for the Pods in the StatefulSet:
for p in 0 1 2; do kubectl get pod "web-$p" --template '{{range $i, $c := .spec.containers}}{{$c.image}}{{end}}'; echo; done
k8s.gcr.io/nginx-slim:0.7
k8s.gcr.io/nginx-slim:0.7
k8s.gcr.io/nginx-slim:0.7
By moving the partition to 0, you allowed the StatefulSet to
continue the update process.
On Delete
The OnDelete update strategy implements the legacy (1.6 and prior) behavior,
When you select this update strategy, the StatefulSet controller will not
automatically update Pods when a modification is made to the StatefulSet's
.spec.template field. This strategy can be selected by setting the
.spec.template.updateStrategy.type to OnDelete.
Deleting StatefulSets
StatefulSet supports both Non-Cascading and Cascading deletion. In a Non-Cascading Delete, the StatefulSet's Pods are not deleted when the StatefulSet is deleted. In a Cascading Delete, both the StatefulSet and its Pods are deleted.
Non-Cascading Delete
In one terminal window, watch the Pods in the StatefulSet.
kubectl get pods -w -l app=nginx
Use kubectl delete to delete the
StatefulSet. Make sure to supply the --cascade=orphan parameter to the
command. This parameter tells Kubernetes to only delete the StatefulSet, and to
not delete any of its Pods.
kubectl delete statefulset web --cascade=orphan
statefulset.apps "web" deleted
Get the Pods, to examine their status:
kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 6m
web-1 1/1 Running 0 7m
web-2 1/1 Running 0 5m
Even though web has been deleted, all of the Pods are still Running and Ready.
Delete web-0:
kubectl delete pod web-0
pod "web-0" deleted
Get the StatefulSet's Pods:
kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
web-1 1/1 Running 0 10m
web-2 1/1 Running 0 7m
As the web StatefulSet has been deleted, web-0 has not been relaunched.
In one terminal, watch the StatefulSet's Pods.
kubectl get pods -w -l app=nginx
In a second terminal, recreate the StatefulSet. Note that, unless
you deleted the nginx Service (which you should not have), you will see
an error indicating that the Service already exists.
kubectl apply -f web.yaml
statefulset.apps/web created
service/nginx unchanged
Ignore the error. It only indicates that an attempt was made to create the nginx headless Service even though that Service already exists.
Examine the output of the kubectl get command running in the first terminal.
kubectl get pods -w -l app=nginx
NAME READY STATUS RESTARTS AGE
web-1 1/1 Running 0 16m
web-2 1/1 Running 0 2m
NAME READY STATUS RESTARTS AGE
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 18s
web-2 1/1 Terminating 0 3m
web-2 0/1 Terminating 0 3m
web-2 0/1 Terminating 0 3m
web-2 0/1 Terminating 0 3m
When the web StatefulSet was recreated, it first relaunched web-0.
Since web-1 was already Running and Ready, when web-0 transitioned to
Running and Ready, it adopted this Pod. Since you recreated the StatefulSet
with replicas equal to 2, once web-0 had been recreated, and once
web-1 had been determined to already be Running and Ready, web-2 was
terminated.
Let's take another look at the contents of the index.html file served by the
Pods' webservers:
for i in 0 1; do kubectl exec -i -t "web-$i" -- curl http://localhost/; done
web-0
web-1
Even though you deleted both the StatefulSet and the web-0 Pod, it still
serves the hostname originally entered into its index.html file. This is
because the StatefulSet never deletes the PersistentVolumes associated with a
Pod. When you recreated the StatefulSet and it relaunched web-0, its original
PersistentVolume was remounted.
Cascading Delete
In one terminal window, watch the Pods in the StatefulSet.
kubectl get pods -w -l app=nginx
In another terminal, delete the StatefulSet again. This time, omit the
--cascade=orphan parameter.
kubectl delete statefulset web
statefulset.apps "web" deleted
Examine the output of the kubectl get command running in the first terminal,
and wait for all of the Pods to transition to Terminating.
kubectl get pods -w -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 11m
web-1 1/1 Running 0 27m
NAME READY STATUS RESTARTS AGE
web-0 1/1 Terminating 0 12m
web-1 1/1 Terminating 0 29m
web-0 0/1 Terminating 0 12m
web-0 0/1 Terminating 0 12m
web-0 0/1 Terminating 0 12m
web-1 0/1 Terminating 0 29m
web-1 0/1 Terminating 0 29m
web-1 0/1 Terminating 0 29m
As you saw in the Scaling Down section, the Pods are terminated one at a time, with respect to the reverse order of their ordinal indices. Before terminating a Pod, the StatefulSet controller waits for the Pod's successor to be completely terminated.
nginx Service manually.
kubectl delete service nginx
service "nginx" deleted
Recreate the StatefulSet and headless Service one more time:
kubectl apply -f web.yaml
service/nginx created
statefulset.apps/web created
When all of the StatefulSet's Pods transition to Running and Ready, retrieve
the contents of their index.html files:
for i in 0 1; do kubectl exec -i -t "web-$i" -- curl http://localhost/; done
web-0
web-1
Even though you completely deleted the StatefulSet, and all of its Pods, the
Pods are recreated with their PersistentVolumes mounted, and web-0 and
web-1 continue to serve their hostnames.
Finally, delete the nginx Service...
kubectl delete service nginx
service "nginx" deleted
...and the web StatefulSet:
kubectl delete statefulset web
statefulset "web" deleted
Pod Management Policy
For some distributed systems, the StatefulSet ordering guarantees are
unnecessary and/or undesirable. These systems require only uniqueness and
identity. To address this, in Kubernetes 1.7, we introduced
.spec.podManagementPolicy to the StatefulSet API Object.
OrderedReady Pod Management
OrderedReady pod management is the default for StatefulSets. It tells the
StatefulSet controller to respect the ordering guarantees demonstrated
above.
Parallel Pod Management
Parallel pod management tells the StatefulSet controller to launch or
terminate all Pods in parallel, and not to wait for Pods to become Running
and Ready or completely terminated prior to launching or terminating another
Pod. This option only affects the behavior for scaling operations. Updates are not affected.
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
podManagementPolicy: "Parallel"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
Download the example above, and save it to a file named web-parallel.yaml
This manifest is identical to the one you downloaded above except that the .spec.podManagementPolicy
of the web StatefulSet is set to Parallel.
In one terminal, watch the Pods in the StatefulSet.
kubectl get pod -l app=nginx -w
In another terminal, create the StatefulSet and Service in the manifest:
kubectl apply -f web-parallel.yaml
service/nginx created
statefulset.apps/web created
Examine the output of the kubectl get command that you executed in the first terminal.
kubectl get pod -l app=nginx -w
NAME READY STATUS RESTARTS AGE
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 0s
web-1 0/1 ContainerCreating 0 0s
web-0 1/1 Running 0 10s
web-1 1/1 Running 0 10s
The StatefulSet controller launched both web-0 and web-1 at the same time.
Keep the second terminal open, and, in another terminal window scale the StatefulSet:
kubectl scale statefulset/web --replicas=4
statefulset.apps/web scaled
Examine the output of the terminal where the kubectl get command is running.
web-3 0/1 Pending 0 0s
web-3 0/1 Pending 0 0s
web-3 0/1 Pending 0 7s
web-3 0/1 ContainerCreating 0 7s
web-2 1/1 Running 0 10s
web-3 1/1 Running 0 26s
The StatefulSet launched two new Pods, and it did not wait for the first to become Running and Ready prior to launching the second.
Cleaning up
You should have two terminals open, ready for you to run kubectl commands as
part of cleanup.
kubectl delete sts web
# sts is an abbreviation for statefulset
You can watch kubectl get to see those Pods being deleted.
kubectl get pod -l app=nginx -w
web-3 1/1 Terminating 0 9m
web-2 1/1 Terminating 0 9m
web-3 1/1 Terminating 0 9m
web-2 1/1 Terminating 0 9m
web-1 1/1 Terminating 0 44m
web-0 1/1 Terminating 0 44m
web-0 0/1 Terminating 0 44m
web-3 0/1 Terminating 0 9m
web-2 0/1 Terminating 0 9m
web-1 0/1 Terminating 0 44m
web-0 0/1 Terminating 0 44m
web-2 0/1 Terminating 0 9m
web-2 0/1 Terminating 0 9m
web-2 0/1 Terminating 0 9m
web-1 0/1 Terminating 0 44m
web-1 0/1 Terminating 0 44m
web-1 0/1 Terminating 0 44m
web-0 0/1 Terminating 0 44m
web-0 0/1 Terminating 0 44m
web-0 0/1 Terminating 0 44m
web-3 0/1 Terminating 0 9m
web-3 0/1 Terminating 0 9m
web-3 0/1 Terminating 0 9m
During deletion, a StatefulSet removes all Pods concurrently; it does not wait for a Pod's ordinal successor to terminate prior to deleting that Pod.
Close the terminal where the kubectl get command is running and delete the nginx
Service:
kubectl delete svc nginx
You also need to delete the persistent storage media for the PersistentVolumes used in this tutorial.
Follow the necessary steps, based on your environment, storage configuration, and provisioning method, to ensure that all storage is reclaimed.
2 - Example: Deploying WordPress and MySQL with Persistent Volumes
This tutorial shows you how to deploy a WordPress site and a MySQL database using Minikube. Both applications use PersistentVolumes and PersistentVolumeClaims to store data.
A PersistentVolume (PV) is a piece of storage in the cluster that has been manually provisioned by an administrator, or dynamically provisioned by Kubernetes using a StorageClass. A PersistentVolumeClaim (PVC) is a request for storage by a user that can be fulfilled by a PV. PersistentVolumes and PersistentVolumeClaims are independent from Pod lifecycles and preserve data through restarting, rescheduling, and even deleting Pods.
Objectives
- Create PersistentVolumeClaims and PersistentVolumes
- Create a
kustomization.yamlwith- a Secret generator
- MySQL resource configs
- WordPress resource configs
- Apply the kustomization directory by
kubectl apply -k ./ - Clean up
Before you begin
You need to have a Kubernetes cluster, and the kubectl command-line tool must be configured to communicate with your cluster. It is recommended to run this tutorial on a cluster with at least two nodes that are not acting as control plane hosts. If you do not already have a cluster, you can create one by using minikube or you can use one of these Kubernetes playgrounds:
To check the version, enterkubectl version.
The example shown on this page works with kubectl 1.14 and above.
Download the following configuration files:
Create PersistentVolumeClaims and PersistentVolumes
MySQL and Wordpress each require a PersistentVolume to store data. Their PersistentVolumeClaims will be created at the deployment step.
Many cluster environments have a default StorageClass installed. When a StorageClass is not specified in the PersistentVolumeClaim, the cluster's default StorageClass is used instead.
When a PersistentVolumeClaim is created, a PersistentVolume is dynamically provisioned based on the StorageClass configuration.
hostPath provisioner. hostPath volumes are only suitable for development and testing. With hostPath volumes, your data lives in /tmp on the node the Pod is scheduled onto and does not move between nodes. If a Pod dies and gets scheduled to another node in the cluster, or the node is rebooted, the data is lost.
hostPath provisioner, the --enable-hostpath-provisioner flag must be set in the controller-manager component.
Create a kustomization.yaml
Add a Secret generator
A Secret is an object that stores a piece of sensitive data like a password or key. Since 1.14, kubectl supports the management of Kubernetes objects using a kustomization file. You can create a Secret by generators in kustomization.yaml.
Add a Secret generator in kustomization.yaml from the following command. You will need to replace YOUR_PASSWORD with the password you want to use.
cat <<EOF >./kustomization.yaml
secretGenerator:
- name: mysql-pass
literals:
- password=YOUR_PASSWORD
EOF
Add resource configs for MySQL and WordPress
The following manifest describes a single-instance MySQL Deployment. The MySQL container mounts the PersistentVolume at /var/lib/mysql. The MYSQL_ROOT_PASSWORD environment variable sets the database password from the Secret.
apiVersion: v1
kind: Service
metadata:
name: wordpress-mysql
labels:
app: wordpress
spec:
ports:
- port: 3306
selector:
app: wordpress
tier: mysql
clusterIP: None
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress-mysql
labels:
app: wordpress
spec:
selector:
matchLabels:
app: wordpress
tier: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: wordpress
tier: mysql
spec:
containers:
- image: mysql:5.6
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
The following manifest describes a single-instance WordPress Deployment. The WordPress container mounts the
PersistentVolume at /var/www/html for website data files. The WORDPRESS_DB_HOST environment variable sets
the name of the MySQL Service defined above, and WordPress will access the database by Service. The
WORDPRESS_DB_PASSWORD environment variable sets the database password from the Secret kustomize generated.
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
spec:
ports:
- port: 80
selector:
app: wordpress
tier: frontend
type: LoadBalancer
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: wp-pv-claim
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
labels:
app: wordpress
spec:
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: Recreate
template:
metadata:
labels:
app: wordpress
tier: frontend
spec:
containers:
- image: wordpress:4.8-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: wordpress-mysql
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
-
Download the MySQL deployment configuration file.
curl -LO https://k8s.io/examples/application/wordpress/mysql-deployment.yaml -
Download the WordPress configuration file.
curl -LO https://k8s.io/examples/application/wordpress/wordpress-deployment.yaml -
Add them to
kustomization.yamlfile.
cat <<EOF >>./kustomization.yaml
resources:
- mysql-deployment.yaml
- wordpress-deployment.yaml
EOF
Apply and Verify
The kustomization.yaml contains all the resources for deploying a WordPress site and a
MySQL database. You can apply the directory by
kubectl apply -k ./
Now you can verify that all objects exist.
-
Verify that the Secret exists by running the following command:
kubectl get secretsThe response should be like this:
NAME TYPE DATA AGE mysql-pass-c57bb4t7mf Opaque 1 9s -
Verify that a PersistentVolume got dynamically provisioned.
kubectl get pvcNote: It can take up to a few minutes for the PVs to be provisioned and bound.The response should be like this:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE mysql-pv-claim Bound pvc-8cbd7b2e-4044-11e9-b2bb-42010a800002 20Gi RWO standard 77s wp-pv-claim Bound pvc-8cd0df54-4044-11e9-b2bb-42010a800002 20Gi RWO standard 77s -
Verify that the Pod is running by running the following command:
kubectl get podsNote: It can take up to a few minutes for the Pod's Status to beRUNNING.The response should be like this:
NAME READY STATUS RESTARTS AGE wordpress-mysql-1894417608-x5dzt 1/1 Running 0 40s -
Verify that the Service is running by running the following command:
kubectl get services wordpressThe response should be like this:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE wordpress LoadBalancer 10.0.0.89 <pending> 80:32406/TCP 4mNote: Minikube can only expose Services throughNodePort. The EXTERNAL-IP is always pending. -
Run the following command to get the IP Address for the WordPress Service:
minikube service wordpress --urlThe response should be like this:
http://1.2.3.4:32406 -
Copy the IP address, and load the page in your browser to view your site.
You should see the WordPress set up page similar to the following screenshot.
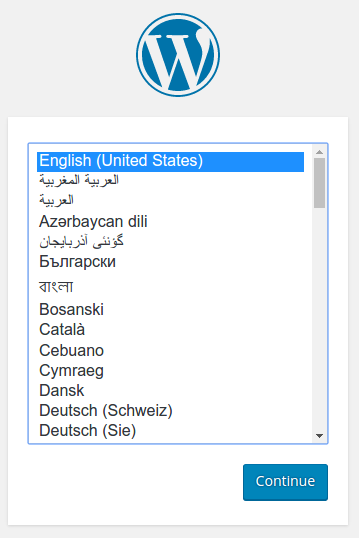
Either install WordPress by creating a username and password or delete your instance.
Cleaning up
-
Run the following command to delete your Secret, Deployments, Services and PersistentVolumeClaims:
kubectl delete -k ./
What's next
- Learn more about Introspection and Debugging
- Learn more about Jobs
- Learn more about Port Forwarding
- Learn how to Get a Shell to a Container
3 - Example: Deploying Cassandra with a StatefulSet
This tutorial shows you how to run Apache Cassandra on Kubernetes. Cassandra, a database, needs persistent storage to provide data durability (application state). In this example, a custom Cassandra seed provider lets the database discover new Cassandra instances as they join the Cassandra cluster.
StatefulSets make it easier to deploy stateful applications into your Kubernetes cluster. For more information on the features used in this tutorial, see StatefulSet.
Cassandra and Kubernetes both use the term node to mean a member of a cluster. In this tutorial, the Pods that belong to the StatefulSet are Cassandra nodes and are members of the Cassandra cluster (called a ring). When those Pods run in your Kubernetes cluster, the Kubernetes control plane schedules those Pods onto Kubernetes Nodes.
When a Cassandra node starts, it uses a seed list to bootstrap discovery of other nodes in the ring. This tutorial deploys a custom Cassandra seed provider that lets the database discover new Cassandra Pods as they appear inside your Kubernetes cluster.
Objectives
- Create and validate a Cassandra headless Service.
- Use a StatefulSet to create a Cassandra ring.
- Validate the StatefulSet.
- Modify the StatefulSet.
- Delete the StatefulSet and its Pods.
Before you begin
You need to have a Kubernetes cluster, and the kubectl command-line tool must be configured to communicate with your cluster. It is recommended to run this tutorial on a cluster with at least two nodes that are not acting as control plane hosts. If you do not already have a cluster, you can create one by using minikube or you can use one of these Kubernetes playgrounds:
To complete this tutorial, you should already have a basic familiarity with Pods, Services, and StatefulSets.
Additional Minikube setup instructions
Minikube defaults to 2048MB of memory and 2 CPU. Running Minikube with the default resource configuration results in insufficient resource errors during this tutorial. To avoid these errors, start Minikube with the following settings:
minikube start --memory 5120 --cpus=4
Creating a headless Service for Cassandra
In Kubernetes, a Service describes a set of Pods that perform the same task.
The following Service is used for DNS lookups between Cassandra Pods and clients within your cluster:
apiVersion: v1
kind: Service
metadata:
labels:
app: cassandra
name: cassandra
spec:
clusterIP: None
ports:
- port: 9042
selector:
app: cassandra
Create a Service to track all Cassandra StatefulSet members from the cassandra-service.yaml file:
kubectl apply -f https://k8s.io/examples/application/cassandra/cassandra-service.yaml
Validating (optional)
Get the Cassandra Service.
kubectl get svc cassandra
The response is
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cassandra ClusterIP None <none> 9042/TCP 45s
If you don't see a Service named cassandra, that means creation failed. Read
Debug Services
for help troubleshooting common issues.
Using a StatefulSet to create a Cassandra ring
The StatefulSet manifest, included below, creates a Cassandra ring that consists of three Pods.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: cassandra
labels:
app: cassandra
spec:
serviceName: cassandra
replicas: 3
selector:
matchLabels:
app: cassandra
template:
metadata:
labels:
app: cassandra
spec:
terminationGracePeriodSeconds: 1800
containers:
- name: cassandra
image: gcr.io/google-samples/cassandra:v13
imagePullPolicy: Always
ports:
- containerPort: 7000
name: intra-node
- containerPort: 7001
name: tls-intra-node
- containerPort: 7199
name: jmx
- containerPort: 9042
name: cql
resources:
limits:
cpu: "500m"
memory: 1Gi
requests:
cpu: "500m"
memory: 1Gi
securityContext:
capabilities:
add:
- IPC_LOCK
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -c
- nodetool drain
env:
- name: MAX_HEAP_SIZE
value: 512M
- name: HEAP_NEWSIZE
value: 100M
- name: CASSANDRA_SEEDS
value: "cassandra-0.cassandra.default.svc.cluster.local"
- name: CASSANDRA_CLUSTER_NAME
value: "K8Demo"
- name: CASSANDRA_DC
value: "DC1-K8Demo"
- name: CASSANDRA_RACK
value: "Rack1-K8Demo"
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
readinessProbe:
exec:
command:
- /bin/bash
- -c
- /ready-probe.sh
initialDelaySeconds: 15
timeoutSeconds: 5
# These volume mounts are persistent. They are like inline claims,
# but not exactly because the names need to match exactly one of
# the stateful pod volumes.
volumeMounts:
- name: cassandra-data
mountPath: /cassandra_data
# These are converted to volume claims by the controller
# and mounted at the paths mentioned above.
# do not use these in production until ssd GCEPersistentDisk or other ssd pd
volumeClaimTemplates:
- metadata:
name: cassandra-data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: fast
resources:
requests:
storage: 1Gi
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fast
provisioner: k8s.io/minikube-hostpath
parameters:
type: pd-ssd
Create the Cassandra StatefulSet from the cassandra-statefulset.yaml file:
# Use this if you are able to apply cassandra-statefulset.yaml unmodified
kubectl apply -f https://k8s.io/examples/application/cassandra/cassandra-statefulset.yaml
If you need to modify cassandra-statefulset.yaml to suit your cluster, download
https://k8s.io/examples/application/cassandra/cassandra-statefulset.yaml and then apply
that manifest, from the folder you saved the modified version into:
# Use this if you needed to modify cassandra-statefulset.yaml locally
kubectl apply -f cassandra-statefulset.yaml
Validating the Cassandra StatefulSet
-
Get the Cassandra StatefulSet:
kubectl get statefulset cassandraThe response should be similar to:
NAME DESIRED CURRENT AGE cassandra 3 0 13sThe
StatefulSetresource deploys Pods sequentially. -
Get the Pods to see the ordered creation status:
kubectl get pods -l="app=cassandra"The response should be similar to:
NAME READY STATUS RESTARTS AGE cassandra-0 1/1 Running 0 1m cassandra-1 0/1 ContainerCreating 0 8sIt can take several minutes for all three Pods to deploy. Once they are deployed, the same command returns output similar to:
NAME READY STATUS RESTARTS AGE cassandra-0 1/1 Running 0 10m cassandra-1 1/1 Running 0 9m cassandra-2 1/1 Running 0 8m -
Run the Cassandra nodetool inside the first Pod, to display the status of the ring.
kubectl exec -it cassandra-0 -- nodetool statusThe response should look something like:
Datacenter: DC1-K8Demo ====================== Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 172.17.0.5 83.57 KiB 32 74.0% e2dd09e6-d9d3-477e-96c5-45094c08db0f Rack1-K8Demo UN 172.17.0.4 101.04 KiB 32 58.8% f89d6835-3a42-4419-92b3-0e62cae1479c Rack1-K8Demo UN 172.17.0.6 84.74 KiB 32 67.1% a6a1e8c2-3dc5-4417-b1a0-26507af2aaad Rack1-K8Demo
Modifying the Cassandra StatefulSet
Use kubectl edit to modify the size of a Cassandra StatefulSet.
-
Run the following command:
kubectl edit statefulset cassandraThis command opens an editor in your terminal. The line you need to change is the
replicasfield. The following sample is an excerpt of the StatefulSet file:# Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: apps/v1 kind: StatefulSet metadata: creationTimestamp: 2016-08-13T18:40:58Z generation: 1 labels: app: cassandra name: cassandra namespace: default resourceVersion: "323" uid: 7a219483-6185-11e6-a910-42010a8a0fc0 spec: replicas: 3 -
Change the number of replicas to 4, and then save the manifest.
The StatefulSet now scales to run with 4 Pods.
-
Get the Cassandra StatefulSet to verify your change:
kubectl get statefulset cassandraThe response should be similar to:
NAME DESIRED CURRENT AGE cassandra 4 4 36m
Cleaning up
Deleting or scaling a StatefulSet down does not delete the volumes associated with the StatefulSet. This setting is for your safety because your data is more valuable than automatically purging all related StatefulSet resources.
-
Run the following commands (chained together into a single command) to delete everything in the Cassandra StatefulSet:
grace=$(kubectl get pod cassandra-0 -o=jsonpath='{.spec.terminationGracePeriodSeconds}') \ && kubectl delete statefulset -l app=cassandra \ && echo "Sleeping ${grace} seconds" 1>&2 \ && sleep $grace \ && kubectl delete persistentvolumeclaim -l app=cassandra -
Run the following command to delete the Service you set up for Cassandra:
kubectl delete service -l app=cassandra
Cassandra container environment variables
The Pods in this tutorial use the gcr.io/google-samples/cassandra:v13
image from Google's container registry.
The Docker image above is based on debian-base
and includes OpenJDK 8.
This image includes a standard Cassandra installation from the Apache Debian repo.
By using environment variables you can change values that are inserted into cassandra.yaml.
| Environment variable | Default value |
|---|---|
CASSANDRA_CLUSTER_NAME |
'Test Cluster' |
CASSANDRA_NUM_TOKENS |
32 |
CASSANDRA_RPC_ADDRESS |
0.0.0.0 |
What's next
- Learn how to Scale a StatefulSet.
- Learn more about the KubernetesSeedProvider
- See more custom Seed Provider Configurations
4 - Running ZooKeeper, A Distributed System Coordinator
This tutorial demonstrates running Apache Zookeeper on Kubernetes using StatefulSets, PodDisruptionBudgets, and PodAntiAffinity.
Before you begin
Before starting this tutorial, you should be familiar with the following Kubernetes concepts:
- Pods
- Cluster DNS
- Headless Services
- PersistentVolumes
- PersistentVolume Provisioning
- StatefulSets
- PodDisruptionBudgets
- PodAntiAffinity
- kubectl CLI
You must have a cluster with at least four nodes, and each node requires at least 2 CPUs and 4 GiB of memory. In this tutorial you will cordon and drain the cluster's nodes. This means that the cluster will terminate and evict all Pods on its nodes, and the nodes will temporarily become unschedulable. You should use a dedicated cluster for this tutorial, or you should ensure that the disruption you cause will not interfere with other tenants.
This tutorial assumes that you have configured your cluster to dynamically provision PersistentVolumes. If your cluster is not configured to do so, you will have to manually provision three 20 GiB volumes before starting this tutorial.
Objectives
After this tutorial, you will know the following.
- How to deploy a ZooKeeper ensemble using StatefulSet.
- How to consistently configure the ensemble.
- How to spread the deployment of ZooKeeper servers in the ensemble.
- How to use PodDisruptionBudgets to ensure service availability during planned maintenance.
ZooKeeper
Apache ZooKeeper is a distributed, open-source coordination service for distributed applications. ZooKeeper allows you to read, write, and observe updates to data. Data are organized in a file system like hierarchy and replicated to all ZooKeeper servers in the ensemble (a set of ZooKeeper servers). All operations on data are atomic and sequentially consistent. ZooKeeper ensures this by using the Zab consensus protocol to replicate a state machine across all servers in the ensemble.
The ensemble uses the Zab protocol to elect a leader, and the ensemble cannot write data until that election is complete. Once complete, the ensemble uses Zab to ensure that it replicates all writes to a quorum before it acknowledges and makes them visible to clients. Without respect to weighted quorums, a quorum is a majority component of the ensemble containing the current leader. For instance, if the ensemble has three servers, a component that contains the leader and one other server constitutes a quorum. If the ensemble can not achieve a quorum, the ensemble cannot write data.
ZooKeeper servers keep their entire state machine in memory, and write every mutation to a durable WAL (Write Ahead Log) on storage media. When a server crashes, it can recover its previous state by replaying the WAL. To prevent the WAL from growing without bound, ZooKeeper servers will periodically snapshot them in memory state to storage media. These snapshots can be loaded directly into memory, and all WAL entries that preceded the snapshot may be discarded.
Creating a ZooKeeper ensemble
The manifest below contains a Headless Service, a Service, a PodDisruptionBudget, and a StatefulSet.
apiVersion: v1
kind: Service
metadata:
name: zk-hs
labels:
app: zk
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zk
---
apiVersion: v1
kind: Service
metadata:
name: zk-cs
labels:
app: zk
spec:
ports:
- port: 2181
name: client
selector:
app: zk
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
selector:
matchLabels:
app: zk
maxUnavailable: 1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zk
spec:
selector:
matchLabels:
app: zk
serviceName: zk-hs
replicas: 3
updateStrategy:
type: RollingUpdate
podManagementPolicy: OrderedReady
template:
metadata:
labels:
app: zk
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zk
topologyKey: "kubernetes.io/hostname"
containers:
- name: kubernetes-zookeeper
imagePullPolicy: Always
image: "k8s.gcr.io/kubernetes-zookeeper:1.0-3.4.10"
resources:
requests:
memory: "1Gi"
cpu: "0.5"
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
command:
- sh
- -c
- "start-zookeeper \
--servers=3 \
--data_dir=/var/lib/zookeeper/data \
--data_log_dir=/var/lib/zookeeper/data/log \
--conf_dir=/opt/zookeeper/conf \
--client_port=2181 \
--election_port=3888 \
--server_port=2888 \
--tick_time=2000 \
--init_limit=10 \
--sync_limit=5 \
--heap=512M \
--max_client_cnxns=60 \
--snap_retain_count=3 \
--purge_interval=12 \
--max_session_timeout=40000 \
--min_session_timeout=4000 \
--log_level=INFO"
readinessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
livenessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 10
timeoutSeconds: 5
volumeMounts:
- name: datadir
mountPath: /var/lib/zookeeper
securityContext:
runAsUser: 1000
fsGroup: 1000
volumeClaimTemplates:
- metadata:
name: datadir
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
Open a terminal, and use the
kubectl apply command to create the
manifest.
kubectl apply -f https://k8s.io/examples/application/zookeeper/zookeeper.yaml
This creates the zk-hs Headless Service, the zk-cs Service,
the zk-pdb PodDisruptionBudget, and the zk StatefulSet.
service/zk-hs created
service/zk-cs created
poddisruptionbudget.policy/zk-pdb created
statefulset.apps/zk created
Use kubectl get to watch the
StatefulSet controller create the StatefulSet's Pods.
kubectl get pods -w -l app=zk
Once the zk-2 Pod is Running and Ready, use CTRL-C to terminate kubectl.
NAME READY STATUS RESTARTS AGE
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 19s
zk-0 1/1 Running 0 40s
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 0s
zk-1 0/1 ContainerCreating 0 0s
zk-1 0/1 Running 0 18s
zk-1 1/1 Running 0 40s
zk-2 0/1 Pending 0 0s
zk-2 0/1 Pending 0 0s
zk-2 0/1 ContainerCreating 0 0s
zk-2 0/1 Running 0 19s
zk-2 1/1 Running 0 40s
The StatefulSet controller creates three Pods, and each Pod has a container with a ZooKeeper server.
Facilitating leader election
Because there is no terminating algorithm for electing a leader in an anonymous network, Zab requires explicit membership configuration to perform leader election. Each server in the ensemble needs to have a unique identifier, all servers need to know the global set of identifiers, and each identifier needs to be associated with a network address.
Use kubectl exec to get the hostnames
of the Pods in the zk StatefulSet.
for i in 0 1 2; do kubectl exec zk-$i -- hostname; done
The StatefulSet controller provides each Pod with a unique hostname based on its ordinal index. The hostnames take the form of <statefulset name>-<ordinal index>. Because the replicas field of the zk StatefulSet is set to 3, the Set's controller creates three Pods with their hostnames set to zk-0, zk-1, and
zk-2.
zk-0
zk-1
zk-2
The servers in a ZooKeeper ensemble use natural numbers as unique identifiers, and store each server's identifier in a file called myid in the server's data directory.
To examine the contents of the myid file for each server use the following command.
for i in 0 1 2; do echo "myid zk-$i";kubectl exec zk-$i -- cat /var/lib/zookeeper/data/myid; done
Because the identifiers are natural numbers and the ordinal indices are non-negative integers, you can generate an identifier by adding 1 to the ordinal.
myid zk-0
1
myid zk-1
2
myid zk-2
3
To get the Fully Qualified Domain Name (FQDN) of each Pod in the zk StatefulSet use the following command.
for i in 0 1 2; do kubectl exec zk-$i -- hostname -f; done
The zk-hs Service creates a domain for all of the Pods,
zk-hs.default.svc.cluster.local.
zk-0.zk-hs.default.svc.cluster.local
zk-1.zk-hs.default.svc.cluster.local
zk-2.zk-hs.default.svc.cluster.local
The A records in Kubernetes DNS resolve the FQDNs to the Pods' IP addresses. If Kubernetes reschedules the Pods, it will update the A records with the Pods' new IP addresses, but the A records names will not change.
ZooKeeper stores its application configuration in a file named zoo.cfg. Use kubectl exec to view the contents of the zoo.cfg file in the zk-0 Pod.
kubectl exec zk-0 -- cat /opt/zookeeper/conf/zoo.cfg
In the server.1, server.2, and server.3 properties at the bottom of
the file, the 1, 2, and 3 correspond to the identifiers in the
ZooKeeper servers' myid files. They are set to the FQDNs for the Pods in
the zk StatefulSet.
clientPort=2181
dataDir=/var/lib/zookeeper/data
dataLogDir=/var/lib/zookeeper/log
tickTime=2000
initLimit=10
syncLimit=2000
maxClientCnxns=60
minSessionTimeout= 4000
maxSessionTimeout= 40000
autopurge.snapRetainCount=3
autopurge.purgeInterval=0
server.1=zk-0.zk-hs.default.svc.cluster.local:2888:3888
server.2=zk-1.zk-hs.default.svc.cluster.local:2888:3888
server.3=zk-2.zk-hs.default.svc.cluster.local:2888:3888
Achieving consensus
Consensus protocols require that the identifiers of each participant be unique. No two participants in the Zab protocol should claim the same unique identifier. This is necessary to allow the processes in the system to agree on which processes have committed which data. If two Pods are launched with the same ordinal, two ZooKeeper servers would both identify themselves as the same server.
kubectl get pods -w -l app=zk
NAME READY STATUS RESTARTS AGE
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 19s
zk-0 1/1 Running 0 40s
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 0s
zk-1 0/1 ContainerCreating 0 0s
zk-1 0/1 Running 0 18s
zk-1 1/1 Running 0 40s
zk-2 0/1 Pending 0 0s
zk-2 0/1 Pending 0 0s
zk-2 0/1 ContainerCreating 0 0s
zk-2 0/1 Running 0 19s
zk-2 1/1 Running 0 40s
The A records for each Pod are entered when the Pod becomes Ready. Therefore,
the FQDNs of the ZooKeeper servers will resolve to a single endpoint, and that
endpoint will be the unique ZooKeeper server claiming the identity configured
in its myid file.
zk-0.zk-hs.default.svc.cluster.local
zk-1.zk-hs.default.svc.cluster.local
zk-2.zk-hs.default.svc.cluster.local
This ensures that the servers properties in the ZooKeepers' zoo.cfg files
represents a correctly configured ensemble.
server.1=zk-0.zk-hs.default.svc.cluster.local:2888:3888
server.2=zk-1.zk-hs.default.svc.cluster.local:2888:3888
server.3=zk-2.zk-hs.default.svc.cluster.local:2888:3888
When the servers use the Zab protocol to attempt to commit a value, they will either achieve consensus and commit the value (if leader election has succeeded and at least two of the Pods are Running and Ready), or they will fail to do so (if either of the conditions are not met). No state will arise where one server acknowledges a write on behalf of another.
Sanity testing the ensemble
The most basic sanity test is to write data to one ZooKeeper server and to read the data from another.
The command below executes the zkCli.sh script to write world to the path /hello on the zk-0 Pod in the ensemble.
kubectl exec zk-0 -- zkCli.sh create /hello world
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
Created /hello
To get the data from the zk-1 Pod use the following command.
kubectl exec zk-1 -- zkCli.sh get /hello
The data that you created on zk-0 is available on all the servers in the
ensemble.
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
world
cZxid = 0x100000002
ctime = Thu Dec 08 15:13:30 UTC 2016
mZxid = 0x100000002
mtime = Thu Dec 08 15:13:30 UTC 2016
pZxid = 0x100000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 0
Providing durable storage
As mentioned in the ZooKeeper Basics section, ZooKeeper commits all entries to a durable WAL, and periodically writes snapshots in memory state, to storage media. Using WALs to provide durability is a common technique for applications that use consensus protocols to achieve a replicated state machine.
Use the kubectl delete command to delete the
zk StatefulSet.
kubectl delete statefulset zk
statefulset.apps "zk" deleted
Watch the termination of the Pods in the StatefulSet.
kubectl get pods -w -l app=zk
When zk-0 if fully terminated, use CTRL-C to terminate kubectl.
zk-2 1/1 Terminating 0 9m
zk-0 1/1 Terminating 0 11m
zk-1 1/1 Terminating 0 10m
zk-2 0/1 Terminating 0 9m
zk-2 0/1 Terminating 0 9m
zk-2 0/1 Terminating 0 9m
zk-1 0/1 Terminating 0 10m
zk-1 0/1 Terminating 0 10m
zk-1 0/1 Terminating 0 10m
zk-0 0/1 Terminating 0 11m
zk-0 0/1 Terminating 0 11m
zk-0 0/1 Terminating 0 11m
Reapply the manifest in zookeeper.yaml.
kubectl apply -f https://k8s.io/examples/application/zookeeper/zookeeper.yaml
This creates the zk StatefulSet object, but the other API objects in the manifest are not modified because they already exist.
Watch the StatefulSet controller recreate the StatefulSet's Pods.
kubectl get pods -w -l app=zk
Once the zk-2 Pod is Running and Ready, use CTRL-C to terminate kubectl.
NAME READY STATUS RESTARTS AGE
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 19s
zk-0 1/1 Running 0 40s
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 0s
zk-1 0/1 ContainerCreating 0 0s
zk-1 0/1 Running 0 18s
zk-1 1/1 Running 0 40s
zk-2 0/1 Pending 0 0s
zk-2 0/1 Pending 0 0s
zk-2 0/1 ContainerCreating 0 0s
zk-2 0/1 Running 0 19s
zk-2 1/1 Running 0 40s
Use the command below to get the value you entered during the sanity test,
from the zk-2 Pod.
kubectl exec zk-2 zkCli.sh get /hello
Even though you terminated and recreated all of the Pods in the zk StatefulSet, the ensemble still serves the original value.
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
world
cZxid = 0x100000002
ctime = Thu Dec 08 15:13:30 UTC 2016
mZxid = 0x100000002
mtime = Thu Dec 08 15:13:30 UTC 2016
pZxid = 0x100000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 0
The volumeClaimTemplates field of the zk StatefulSet's spec specifies a PersistentVolume provisioned for each Pod.
volumeClaimTemplates:
- metadata:
name: datadir
annotations:
volume.alpha.kubernetes.io/storage-class: anything
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 20Gi
The StatefulSet controller generates a PersistentVolumeClaim for each Pod in
the StatefulSet.
Use the following command to get the StatefulSet's PersistentVolumeClaims.
kubectl get pvc -l app=zk
When the StatefulSet recreated its Pods, it remounts the Pods' PersistentVolumes.
NAME STATUS VOLUME CAPACITY ACCESSMODES AGE
datadir-zk-0 Bound pvc-bed742cd-bcb1-11e6-994f-42010a800002 20Gi RWO 1h
datadir-zk-1 Bound pvc-bedd27d2-bcb1-11e6-994f-42010a800002 20Gi RWO 1h
datadir-zk-2 Bound pvc-bee0817e-bcb1-11e6-994f-42010a800002 20Gi RWO 1h
The volumeMounts section of the StatefulSet's container template mounts the PersistentVolumes in the ZooKeeper servers' data directories.
volumeMounts:
- name: datadir
mountPath: /var/lib/zookeeper
When a Pod in the zk StatefulSet is (re)scheduled, it will always have the
same PersistentVolume mounted to the ZooKeeper server's data directory.
Even when the Pods are rescheduled, all the writes made to the ZooKeeper
servers' WALs, and all their snapshots, remain durable.
Ensuring consistent configuration
As noted in the Facilitating Leader Election and Achieving Consensus sections, the servers in a ZooKeeper ensemble require consistent configuration to elect a leader and form a quorum. They also require consistent configuration of the Zab protocol in order for the protocol to work correctly over a network. In our example we achieve consistent configuration by embedding the configuration directly into the manifest.
Get the zk StatefulSet.
kubectl get sts zk -o yaml
…
command:
- sh
- -c
- "start-zookeeper \
--servers=3 \
--data_dir=/var/lib/zookeeper/data \
--data_log_dir=/var/lib/zookeeper/data/log \
--conf_dir=/opt/zookeeper/conf \
--client_port=2181 \
--election_port=3888 \
--server_port=2888 \
--tick_time=2000 \
--init_limit=10 \
--sync_limit=5 \
--heap=512M \
--max_client_cnxns=60 \
--snap_retain_count=3 \
--purge_interval=12 \
--max_session_timeout=40000 \
--min_session_timeout=4000 \
--log_level=INFO"
…
The command used to start the ZooKeeper servers passed the configuration as command line parameter. You can also use environment variables to pass configuration to the ensemble.
Configuring logging
One of the files generated by the zkGenConfig.sh script controls ZooKeeper's logging.
ZooKeeper uses Log4j, and, by default,
it uses a time and size based rolling file appender for its logging configuration.
Use the command below to get the logging configuration from one of Pods in the zk StatefulSet.
kubectl exec zk-0 cat /usr/etc/zookeeper/log4j.properties
The logging configuration below will cause the ZooKeeper process to write all of its logs to the standard output file stream.
zookeeper.root.logger=CONSOLE
zookeeper.console.threshold=INFO
log4j.rootLogger=${zookeeper.root.logger}
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n
This is the simplest possible way to safely log inside the container. Because the applications write logs to standard out, Kubernetes will handle log rotation for you. Kubernetes also implements a sane retention policy that ensures application logs written to standard out and standard error do not exhaust local storage media.
Use kubectl logs to retrieve the last 20 log lines from one of the Pods.
kubectl logs zk-0 --tail 20
You can view application logs written to standard out or standard error using kubectl logs and from the Kubernetes Dashboard.
2016-12-06 19:34:16,236 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52740
2016-12-06 19:34:16,237 [myid:1] - INFO [Thread-1136:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52740 (no session established for client)
2016-12-06 19:34:26,155 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:52749
2016-12-06 19:34:26,155 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52749
2016-12-06 19:34:26,156 [myid:1] - INFO [Thread-1137:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52749 (no session established for client)
2016-12-06 19:34:26,222 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:52750
2016-12-06 19:34:26,222 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52750
2016-12-06 19:34:26,226 [myid:1] - INFO [Thread-1138:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52750 (no session established for client)
2016-12-06 19:34:36,151 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:52760
2016-12-06 19:34:36,152 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52760
2016-12-06 19:34:36,152 [myid:1] - INFO [Thread-1139:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52760 (no session established for client)
2016-12-06 19:34:36,230 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:52761
2016-12-06 19:34:36,231 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52761
2016-12-06 19:34:36,231 [myid:1] - INFO [Thread-1140:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52761 (no session established for client)
2016-12-06 19:34:46,149 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:52767
2016-12-06 19:34:46,149 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52767
2016-12-06 19:34:46,149 [myid:1] - INFO [Thread-1141:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52767 (no session established for client)
2016-12-06 19:34:46,230 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@192] - Accepted socket connection from /127.0.0.1:52768
2016-12-06 19:34:46,230 [myid:1] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@827] - Processing ruok command from /127.0.0.1:52768
2016-12-06 19:34:46,230 [myid:1] - INFO [Thread-1142:NIOServerCnxn@1008] - Closed socket connection for client /127.0.0.1:52768 (no session established for client)
Kubernetes integrates with many logging solutions. You can choose a logging solution that best fits your cluster and applications. For cluster-level logging and aggregation, consider deploying a sidecar container to rotate and ship your logs.
Configuring a non-privileged user
The best practices to allow an application to run as a privileged user inside of a container are a matter of debate. If your organization requires that applications run as a non-privileged user you can use a SecurityContext to control the user that the entry point runs as.
The zk StatefulSet's Pod template contains a SecurityContext.
securityContext:
runAsUser: 1000
fsGroup: 1000
In the Pods' containers, UID 1000 corresponds to the zookeeper user and GID 1000 corresponds to the zookeeper group.
Get the ZooKeeper process information from the zk-0 Pod.
kubectl exec zk-0 -- ps -elf
As the runAsUser field of the securityContext object is set to 1000,
instead of running as root, the ZooKeeper process runs as the zookeeper user.
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S zookeep+ 1 0 0 80 0 - 1127 - 20:46 ? 00:00:00 sh -c zkGenConfig.sh && zkServer.sh start-foreground
0 S zookeep+ 27 1 0 80 0 - 1155556 - 20:46 ? 00:00:19 /usr/lib/jvm/java-8-openjdk-amd64/bin/java -Dzookeeper.log.dir=/var/log/zookeeper -Dzookeeper.root.logger=INFO,CONSOLE -cp /usr/bin/../build/classes:/usr/bin/../build/lib/*.jar:/usr/bin/../share/zookeeper/zookeeper-3.4.9.jar:/usr/bin/../share/zookeeper/slf4j-log4j12-1.6.1.jar:/usr/bin/../share/zookeeper/slf4j-api-1.6.1.jar:/usr/bin/../share/zookeeper/netty-3.10.5.Final.jar:/usr/bin/../share/zookeeper/log4j-1.2.16.jar:/usr/bin/../share/zookeeper/jline-0.9.94.jar:/usr/bin/../src/java/lib/*.jar:/usr/bin/../etc/zookeeper: -Xmx2G -Xms2G -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=false org.apache.zookeeper.server.quorum.QuorumPeerMain /usr/bin/../etc/zookeeper/zoo.cfg
By default, when the Pod's PersistentVolumes is mounted to the ZooKeeper server's data directory, it is only accessible by the root user. This configuration prevents the ZooKeeper process from writing to its WAL and storing its snapshots.
Use the command below to get the file permissions of the ZooKeeper data directory on the zk-0 Pod.
kubectl exec -ti zk-0 -- ls -ld /var/lib/zookeeper/data
Because the fsGroup field of the securityContext object is set to 1000, the ownership of the Pods' PersistentVolumes is set to the zookeeper group, and the ZooKeeper process is able to read and write its data.
drwxr-sr-x 3 zookeeper zookeeper 4096 Dec 5 20:45 /var/lib/zookeeper/data
Managing the ZooKeeper process
The ZooKeeper documentation mentions that "You will want to have a supervisory process that manages each of your ZooKeeper server processes (JVM)." Utilizing a watchdog (supervisory process) to restart failed processes in a distributed system is a common pattern. When deploying an application in Kubernetes, rather than using an external utility as a supervisory process, you should use Kubernetes as the watchdog for your application.
Updating the ensemble
The zk StatefulSet is configured to use the RollingUpdate update strategy.
You can use kubectl patch to update the number of cpus allocated to the servers.
kubectl patch sts zk --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/resources/requests/cpu", "value":"0.3"}]'
statefulset.apps/zk patched
Use kubectl rollout status to watch the status of the update.
kubectl rollout status sts/zk
waiting for statefulset rolling update to complete 0 pods at revision zk-5db4499664...
Waiting for 1 pods to be ready...
Waiting for 1 pods to be ready...
waiting for statefulset rolling update to complete 1 pods at revision zk-5db4499664...
Waiting for 1 pods to be ready...
Waiting for 1 pods to be ready...
waiting for statefulset rolling update to complete 2 pods at revision zk-5db4499664...
Waiting for 1 pods to be ready...
Waiting for 1 pods to be ready...
statefulset rolling update complete 3 pods at revision zk-5db4499664...
This terminates the Pods, one at a time, in reverse ordinal order, and recreates them with the new configuration. This ensures that quorum is maintained during a rolling update.
Use the kubectl rollout history command to view a history or previous configurations.
kubectl rollout history sts/zk
The output is similar to this:
statefulsets "zk"
REVISION
1
2
Use the kubectl rollout undo command to roll back the modification.
kubectl rollout undo sts/zk
The output is similar to this:
statefulset.apps/zk rolled back
Handling process failure
Restart Policies control how
Kubernetes handles process failures for the entry point of the container in a Pod.
For Pods in a StatefulSet, the only appropriate RestartPolicy is Always, and this
is the default value. For stateful applications you should never override
the default policy.
Use the following command to examine the process tree for the ZooKeeper server running in the zk-0 Pod.
kubectl exec zk-0 -- ps -ef
The command used as the container's entry point has PID 1, and the ZooKeeper process, a child of the entry point, has PID 27.
UID PID PPID C STIME TTY TIME CMD
zookeep+ 1 0 0 15:03 ? 00:00:00 sh -c zkGenConfig.sh && zkServer.sh start-foreground
zookeep+ 27 1 0 15:03 ? 00:00:03 /usr/lib/jvm/java-8-openjdk-amd64/bin/java -Dzookeeper.log.dir=/var/log/zookeeper -Dzookeeper.root.logger=INFO,CONSOLE -cp /usr/bin/../build/classes:/usr/bin/../build/lib/*.jar:/usr/bin/../share/zookeeper/zookeeper-3.4.9.jar:/usr/bin/../share/zookeeper/slf4j-log4j12-1.6.1.jar:/usr/bin/../share/zookeeper/slf4j-api-1.6.1.jar:/usr/bin/../share/zookeeper/netty-3.10.5.Final.jar:/usr/bin/../share/zookeeper/log4j-1.2.16.jar:/usr/bin/../share/zookeeper/jline-0.9.94.jar:/usr/bin/../src/java/lib/*.jar:/usr/bin/../etc/zookeeper: -Xmx2G -Xms2G -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=false org.apache.zookeeper.server.quorum.QuorumPeerMain /usr/bin/../etc/zookeeper/zoo.cfg
In another terminal watch the Pods in the zk StatefulSet with the following command.
kubectl get pod -w -l app=zk
In another terminal, terminate the ZooKeeper process in Pod zk-0 with the following command.
kubectl exec zk-0 -- pkill java
The termination of the ZooKeeper process caused its parent process to terminate. Because the RestartPolicy of the container is Always, it restarted the parent process.
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Running 0 21m
zk-1 1/1 Running 0 20m
zk-2 1/1 Running 0 19m
NAME READY STATUS RESTARTS AGE
zk-0 0/1 Error 0 29m
zk-0 0/1 Running 1 29m
zk-0 1/1 Running 1 29m
If your application uses a script (such as zkServer.sh) to launch the process
that implements the application's business logic, the script must terminate with the
child process. This ensures that Kubernetes will restart the application's
container when the process implementing the application's business logic fails.
Testing for liveness
Configuring your application to restart failed processes is not enough to keep a distributed system healthy. There are scenarios where a system's processes can be both alive and unresponsive, or otherwise unhealthy. You should use liveness probes to notify Kubernetes that your application's processes are unhealthy and it should restart them.
The Pod template for the zk StatefulSet specifies a liveness probe.
livenessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 15
timeoutSeconds: 5
The probe calls a bash script that uses the ZooKeeper ruok four letter
word to test the server's health.
OK=$(echo ruok | nc 127.0.0.1 $1)
if [ "$OK" == "imok" ]; then
exit 0
else
exit 1
fi
In one terminal window, use the following command to watch the Pods in the zk StatefulSet.
kubectl get pod -w -l app=zk
In another window, using the following command to delete the zookeeper-ready script from the file system of Pod zk-0.
kubectl exec zk-0 -- rm /opt/zookeeper/bin/zookeeper-ready
When the liveness probe for the ZooKeeper process fails, Kubernetes will automatically restart the process for you, ensuring that unhealthy processes in the ensemble are restarted.
kubectl get pod -w -l app=zk
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Running 0 1h
zk-1 1/1 Running 0 1h
zk-2 1/1 Running 0 1h
NAME READY STATUS RESTARTS AGE
zk-0 0/1 Running 0 1h
zk-0 0/1 Running 1 1h
zk-0 1/1 Running 1 1h
Testing for readiness
Readiness is not the same as liveness. If a process is alive, it is scheduled and healthy. If a process is ready, it is able to process input. Liveness is a necessary, but not sufficient, condition for readiness. There are cases, particularly during initialization and termination, when a process can be alive but not ready.
If you specify a readiness probe, Kubernetes will ensure that your application's processes will not receive network traffic until their readiness checks pass.
For a ZooKeeper server, liveness implies readiness. Therefore, the readiness
probe from the zookeeper.yaml manifest is identical to the liveness probe.
readinessProbe:
exec:
command:
- sh
- -c
- "zookeeper-ready 2181"
initialDelaySeconds: 15
timeoutSeconds: 5
Even though the liveness and readiness probes are identical, it is important to specify both. This ensures that only healthy servers in the ZooKeeper ensemble receive network traffic.
Tolerating Node failure
ZooKeeper needs a quorum of servers to successfully commit mutations to data. For a three server ensemble, two servers must be healthy for writes to succeed. In quorum based systems, members are deployed across failure domains to ensure availability. To avoid an outage, due to the loss of an individual machine, best practices preclude co-locating multiple instances of the application on the same machine.
By default, Kubernetes may co-locate Pods in a StatefulSet on the same node.
For the three server ensemble you created, if two servers are on the same node, and that node fails,
the clients of your ZooKeeper service will experience an outage until at least one of the Pods can be rescheduled.
You should always provision additional capacity to allow the processes of critical
systems to be rescheduled in the event of node failures. If you do so, then the
outage will only last until the Kubernetes scheduler reschedules one of the ZooKeeper
servers. However, if you want your service to tolerate node failures with no downtime,
you should set podAntiAffinity.
Use the command below to get the nodes for Pods in the zk StatefulSet.
for i in 0 1 2; do kubectl get pod zk-$i --template {{.spec.nodeName}}; echo ""; done
All of the Pods in the zk StatefulSet are deployed on different nodes.
kubernetes-node-cxpk
kubernetes-node-a5aq
kubernetes-node-2g2d
This is because the Pods in the zk StatefulSet have a PodAntiAffinity specified.
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zk
topologyKey: "kubernetes.io/hostname"
The requiredDuringSchedulingIgnoredDuringExecution field tells the
Kubernetes Scheduler that it should never co-locate two Pods which have app label
as zk in the domain defined by the topologyKey. The topologyKey
kubernetes.io/hostname indicates that the domain is an individual node. Using
different rules, labels, and selectors, you can extend this technique to spread
your ensemble across physical, network, and power failure domains.
Surviving maintenance
In this section you will cordon and drain nodes. If you are using this tutorial on a shared cluster, be sure that this will not adversely affect other tenants.
The previous section showed you how to spread your Pods across nodes to survive unplanned node failures, but you also need to plan for temporary node failures that occur due to planned maintenance.
Use this command to get the nodes in your cluster.
kubectl get nodes
This tutorial assumes a cluster with at least four nodes. If the cluster has more than four, use kubectl cordon to cordon all but four nodes. Constraining to four nodes will ensure Kubernetes encounters affinity and PodDisruptionBudget constraints when scheduling zookeeper Pods in the following maintenance simulation.
kubectl cordon <node-name>
Use this command to get the zk-pdb PodDisruptionBudget.
kubectl get pdb zk-pdb
The max-unavailable field indicates to Kubernetes that at most one Pod from
zk StatefulSet can be unavailable at any time.
NAME MIN-AVAILABLE MAX-UNAVAILABLE ALLOWED-DISRUPTIONS AGE
zk-pdb N/A 1 1
In one terminal, use this command to watch the Pods in the zk StatefulSet.
kubectl get pods -w -l app=zk
In another terminal, use this command to get the nodes that the Pods are currently scheduled on.
for i in 0 1 2; do kubectl get pod zk-$i --template {{.spec.nodeName}}; echo ""; done
The output is similar to this:
kubernetes-node-pb41
kubernetes-node-ixsl
kubernetes-node-i4c4
Use kubectl drain to cordon and
drain the node on which the zk-0 Pod is scheduled.
kubectl drain $(kubectl get pod zk-0 --template {{.spec.nodeName}}) --ignore-daemonsets --force --delete-emptydir-data
The output is similar to this:
node "kubernetes-node-pb41" cordoned
WARNING: Deleting pods not managed by ReplicationController, ReplicaSet, Job, or DaemonSet: fluentd-cloud-logging-kubernetes-node-pb41, kube-proxy-kubernetes-node-pb41; Ignoring DaemonSet-managed pods: node-problem-detector-v0.1-o5elz
pod "zk-0" deleted
node "kubernetes-node-pb41" drained
As there are four nodes in your cluster, kubectl drain, succeeds and the
zk-0 is rescheduled to another node.
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Running 2 1h
zk-1 1/1 Running 0 1h
zk-2 1/1 Running 0 1h
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 51s
zk-0 1/1 Running 0 1m
Keep watching the StatefulSet's Pods in the first terminal and drain the node on which
zk-1 is scheduled.
kubectl drain $(kubectl get pod zk-1 --template {{.spec.nodeName}}) --ignore-daemonsets --force --delete-emptydir-data
The output is similar to this:
"kubernetes-node-ixsl" cordoned
WARNING: Deleting pods not managed by ReplicationController, ReplicaSet, Job, or DaemonSet: fluentd-cloud-logging-kubernetes-node-ixsl, kube-proxy-kubernetes-node-ixsl; Ignoring DaemonSet-managed pods: node-problem-detector-v0.1-voc74
pod "zk-1" deleted
node "kubernetes-node-ixsl" drained
The zk-1 Pod cannot be scheduled because the zk StatefulSet contains a PodAntiAffinity rule preventing
co-location of the Pods, and as only two nodes are schedulable, the Pod will remain in a Pending state.
kubectl get pods -w -l app=zk
The output is similar to this:
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Running 2 1h
zk-1 1/1 Running 0 1h
zk-2 1/1 Running 0 1h
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 51s
zk-0 1/1 Running 0 1m
zk-1 1/1 Terminating 0 2h
zk-1 0/1 Terminating 0 2h
zk-1 0/1 Terminating 0 2h
zk-1 0/1 Terminating 0 2h
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 0s
Continue to watch the Pods of the StatefulSet, and drain the node on which
zk-2 is scheduled.
kubectl drain $(kubectl get pod zk-2 --template {{.spec.nodeName}}) --ignore-daemonsets --force --delete-emptydir-data
The output is similar to this:
node "kubernetes-node-i4c4" cordoned
WARNING: Deleting pods not managed by ReplicationController, ReplicaSet, Job, or DaemonSet: fluentd-cloud-logging-kubernetes-node-i4c4, kube-proxy-kubernetes-node-i4c4; Ignoring DaemonSet-managed pods: node-problem-detector-v0.1-dyrog
WARNING: Ignoring DaemonSet-managed pods: node-problem-detector-v0.1-dyrog; Deleting pods not managed by ReplicationController, ReplicaSet, Job, or DaemonSet: fluentd-cloud-logging-kubernetes-node-i4c4, kube-proxy-kubernetes-node-i4c4
There are pending pods when an error occurred: Cannot evict pod as it would violate the pod's disruption budget.
pod/zk-2
Use CTRL-C to terminate to kubectl.
You cannot drain the third node because evicting zk-2 would violate zk-budget. However, the node will remain cordoned.
Use zkCli.sh to retrieve the value you entered during the sanity test from zk-0.
kubectl exec zk-0 zkCli.sh get /hello
The service is still available because its PodDisruptionBudget is respected.
WatchedEvent state:SyncConnected type:None path:null
world
cZxid = 0x200000002
ctime = Wed Dec 07 00:08:59 UTC 2016
mZxid = 0x200000002
mtime = Wed Dec 07 00:08:59 UTC 2016
pZxid = 0x200000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 0
Use kubectl uncordon to uncordon the first node.
kubectl uncordon kubernetes-node-pb41
The output is similar to this:
node "kubernetes-node-pb41" uncordoned
zk-1 is rescheduled on this node. Wait until zk-1 is Running and Ready.
kubectl get pods -w -l app=zk
The output is similar to this:
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Running 2 1h
zk-1 1/1 Running 0 1h
zk-2 1/1 Running 0 1h
NAME READY STATUS RESTARTS AGE
zk-0 1/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Terminating 2 2h
zk-0 0/1 Pending 0 0s
zk-0 0/1 Pending 0 0s
zk-0 0/1 ContainerCreating 0 0s
zk-0 0/1 Running 0 51s
zk-0 1/1 Running 0 1m
zk-1 1/1 Terminating 0 2h
zk-1 0/1 Terminating 0 2h
zk-1 0/1 Terminating 0 2h
zk-1 0/1 Terminating 0 2h
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 0s
zk-1 0/1 Pending 0 12m
zk-1 0/1 ContainerCreating 0 12m
zk-1 0/1 Running 0 13m
zk-1 1/1 Running 0 13m
Attempt to drain the node on which zk-2 is scheduled.
kubectl drain $(kubectl get pod zk-2 --template {{.spec.nodeName}}) --ignore-daemonsets --force --delete-emptydir-data
The output is similar to this:
node "kubernetes-node-i4c4" already cordoned
WARNING: Deleting pods not managed by ReplicationController, ReplicaSet, Job, or DaemonSet: fluentd-cloud-logging-kubernetes-node-i4c4, kube-proxy-kubernetes-node-i4c4; Ignoring DaemonSet-managed pods: node-problem-detector-v0.1-dyrog
pod "heapster-v1.2.0-2604621511-wht1r" deleted
pod "zk-2" deleted
node "kubernetes-node-i4c4" drained
This time kubectl drain succeeds.
Uncordon the second node to allow zk-2 to be rescheduled.
kubectl uncordon kubernetes-node-ixsl
The output is similar to this:
node "kubernetes-node-ixsl" uncordoned
You can use kubectl drain in conjunction with PodDisruptionBudgets to ensure that your services remain available during maintenance.
If drain is used to cordon nodes and evict pods prior to taking the node offline for maintenance,
services that express a disruption budget will have that budget respected.
You should always allocate additional capacity for critical services so that their Pods can be immediately rescheduled.
Cleaning up
- Use
kubectl uncordonto uncordon all the nodes in your cluster. - You must delete the persistent storage media for the PersistentVolumes used in this tutorial. Follow the necessary steps, based on your environment, storage configuration, and provisioning method, to ensure that all storage is reclaimed.