쿠버네티스 확장
쿠버네티스 클러스터의 동작을 변경하는 다양한 방법
쿠버네티스는 매우 유연하게 구성할 수 있고 확장 가능하다. 결과적으로
쿠버네티스 프로젝트를 포크하거나 코드에 패치를 제출할 필요가
거의 없다.
이 가이드는 쿠버네티스 클러스터를 사용자 정의하기 위한 옵션을 설명한다.
쿠버네티스 클러스터를 업무 환경의 요구에 맞게
조정하는 방법을 이해하려는 클러스터 운영자를 대상으로 한다.
잠재적인 플랫폼 개발자 또는 쿠버네티스 프로젝트 컨트리뷰터인 개발자에게도
어떤 익스텐션(extension) 포인트와 패턴이 있는지,
그리고 그것의 트레이드오프와 제약을 이해하는 데 도움이 될 것이다.
개요
사용자 정의 방식은 크게 플래그, 로컬 구성 파일 또는 API 리소스 변경만 포함하는 구성 과 추가 프로그램이나 서비스 실행과 관련된 익스텐션 으로 나눌 수 있다. 이 문서는 주로 익스텐션에 관한 것이다.
구성
구성 파일 및 플래그 는 온라인 문서의 레퍼런스 섹션에 각 바이너리 별로 문서화되어 있다.
호스팅된 쿠버네티스 서비스 또는 매니지드 설치 환경의 배포판에서 플래그 및 구성 파일을 항상 변경할 수 있는 것은 아니다. 변경 가능한 경우 일반적으로 클러스터 관리자만 변경할 수 있다. 또한 향후 쿠버네티스 버전에서 변경될 수 있으며, 이를 설정하려면 프로세스를 다시 시작해야 할 수도 있다. 이러한 이유로 다른 옵션이 없는 경우에만 사용해야 한다.
리소스쿼터, 파드시큐리티폴리시(PodSecurityPolicy), 네트워크폴리시 및 역할 기반 접근 제어(RBAC)와 같은 빌트인 정책 API(built-in Policy API) 는 기본적으로 제공되는 쿠버네티스 API이다. API는 일반적으로 호스팅된 쿠버네티스 서비스 및 매니지드 쿠버네티스 설치 환경과 함께 사용된다. 그것들은 선언적이며 파드와 같은 다른 쿠버네티스 리소스와 동일한 규칙을 사용하므로, 새로운 클러스터 구성을 반복할 수 있고 애플리케이션과 동일한 방식으로 관리할 수 있다. 또한, 이들 API가 안정적인 경우, 다른 쿠버네티스 API와 같이 정의된 지원 정책을 사용할 수 있다. 이러한 이유로 인해 구성 파일 과 플래그 보다 선호된다.
익스텐션
익스텐션은 쿠버네티스를 확장하고 쿠버네티스와 긴밀하게 통합되는 소프트웨어 컴포넌트이다.
이들 컴포넌트는 쿠버네티스가 새로운 유형과 새로운 종류의 하드웨어를 지원할 수 있게 해준다.
많은 클러스터 관리자가 호스팅 또는 배포판 쿠버네티스 인스턴스를 사용한다.
이러한 클러스터들은 미리 설치된 익스텐션을 포함한다. 결과적으로 대부분의
쿠버네티스 사용자는 익스텐션을 설치할 필요가 없고, 새로운 익스텐션을 만들 필요가 있는 사용자는 더 적다.
익스텐션 패턴
쿠버네티스는 클라이언트 프로그램을 작성하여 자동화 되도록 설계되었다.
쿠버네티스 API를 읽고 쓰는 프로그램은 유용한 자동화를 제공할 수 있다.
자동화 는 클러스터 상에서 또는 클러스터 밖에서 실행할 수 있다. 이 문서의 지침에 따라
고가용성과 강력한 자동화를 작성할 수 있다.
자동화는 일반적으로 호스트 클러스터 및 매니지드 설치 환경을 포함한 모든
쿠버네티스 클러스터에서 작동한다.
쿠버네티스와 잘 작동하는 클라이언트 프로그램을 작성하기 위한 특정 패턴은 컨트롤러 패턴이라고 한다.
컨트롤러는 일반적으로 오브젝트의 .spec을 읽고, 가능한 경우 수행한 다음
오브젝트의 .status를 업데이트 한다.
컨트롤러는 쿠버네티스의 클라이언트이다. 쿠버네티스가 클라이언트이고
원격 서비스를 호출할 때 이를 웹훅(Webhook) 이라고 한다. 원격 서비스를
웹훅 백엔드 라고 한다. 컨트롤러와 마찬가지로 웹훅은 장애 지점을
추가한다.
웹훅 모델에서 쿠버네티스는 원격 서비스에 네트워크 요청을 한다.
바이너리 플러그인 모델에서 쿠버네티스는 바이너리(프로그램)를 실행한다.
바이너리 플러그인은 kubelet(예:
Flex Volume 플러그인과
네트워크 플러그인)과
kubectl에서 사용한다.
아래는 익스텐션 포인트가 쿠버네티스 컨트롤 플레인과 상호 작용하는 방법을
보여주는 다이어그램이다.
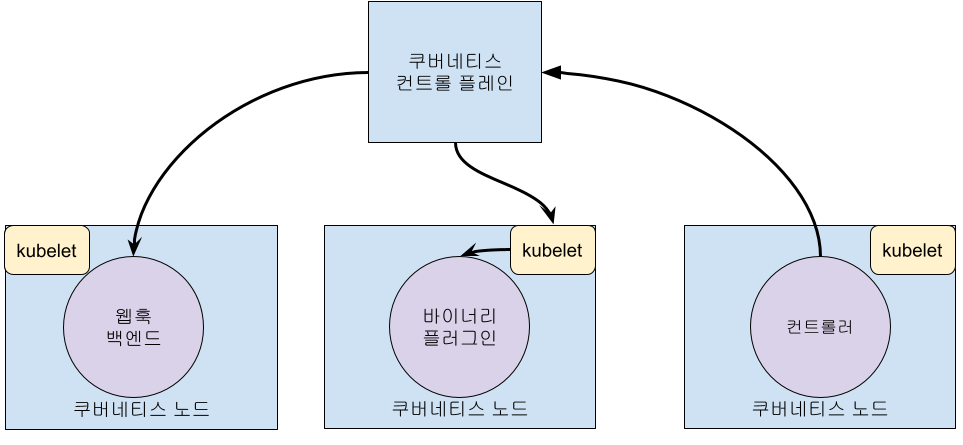
익스텐션 포인트
이 다이어그램은 쿠버네티스 시스템의 익스텐션 포인트를 보여준다.
- 사용자는 종종
kubectl을 사용하여 쿠버네티스 API와 상호 작용한다. Kubectl 플러그인은 kubectl 바이너리를 확장한다. 개별 사용자의 로컬 환경에만 영향을 미치므로 사이트 전체 정책을 적용할 수는 없다.
- apiserver는 모든 요청을 처리한다. apiserver의 여러 유형의 익스텐션 포인트는 요청을 인증하거나, 콘텐츠를 기반으로 요청을 차단하거나, 콘텐츠를 편집하고, 삭제 처리를 허용한다. 이 내용은 API 접근 익스텐션 섹션에 설명되어 있다.
- apiserver는 다양한 종류의 리소스 를 제공한다.
pods와 같은 빌트인 리소스 종류 는 쿠버네티스 프로젝트에 의해 정의되며 변경할 수 없다. 직접 정의한 리소스를 추가할 수도 있고, 커스텀 리소스 섹션에 설명된 대로 커스텀 리소스 라고 부르는 다른 프로젝트에서 정의한 리소스를 추가할 수도 있다. 커스텀 리소스는 종종 API 접근 익스텐션과 함께 사용된다.
- 쿠버네티스 스케줄러는 파드를 배치할 노드를 결정한다. 스케줄링을 확장하는 몇 가지 방법이 있다. 이들은 스케줄러 익스텐션 섹션에 설명되어 있다.
- 쿠버네티스의 많은 동작은 API-Server의 클라이언트인 컨트롤러(Controller)라는 프로그램으로 구현된다. 컨트롤러는 종종 커스텀 리소스와 함께 사용된다.
- kubelet은 서버에서 실행되며 파드가 클러스터 네트워크에서 자체 IP를 가진 가상 서버처럼 보이도록 한다. 네트워크 플러그인을 사용하면 다양한 파드 네트워킹 구현이 가능하다.
- kubelet은 컨테이너의 볼륨을 마운트 및 마운트 해제한다. 새로운 유형의 스토리지는 스토리지 플러그인을 통해 지원될 수 있다.
어디서부터 시작해야 할지 모르겠다면, 이 플로우 차트가 도움이 될 수 있다. 일부 솔루션에는 여러 유형의 익스텐션이 포함될 수 있다.
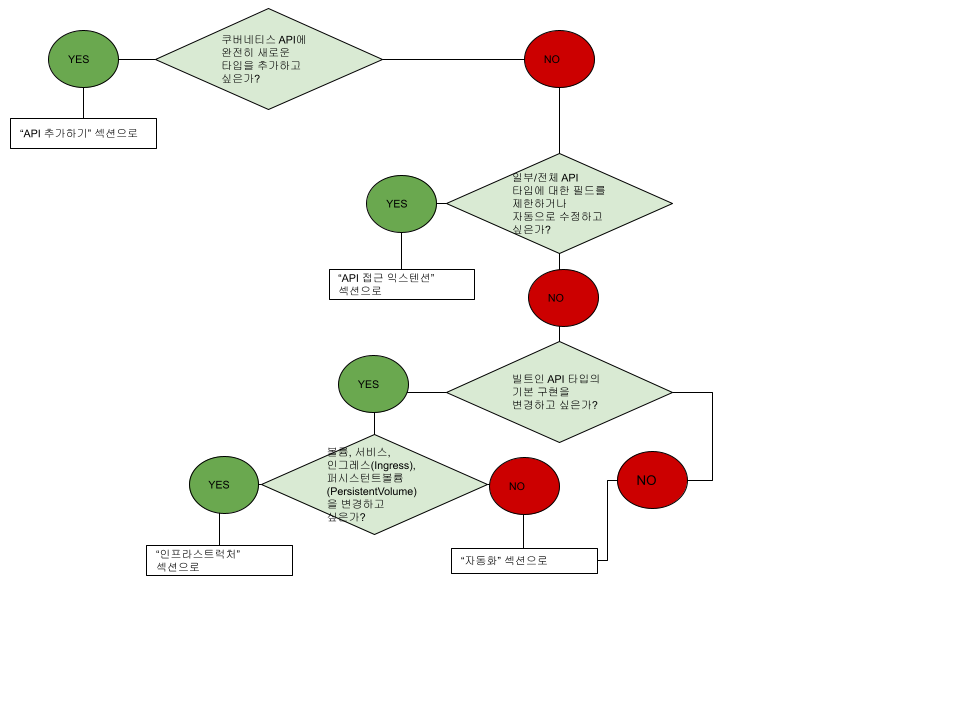
API 익스텐션
사용자 정의 유형
새 컨트롤러, 애플리케이션 구성 오브젝트 또는 기타 선언적 API를 정의하고 kubectl 과 같은 쿠버네티스 도구를 사용하여 관리하려면 쿠버네티스에 커스텀 리소스를 추가하자.
애플리케이션, 사용자 또는 모니터링 데이터의 데이터 저장소로 커스텀 리소스를 사용하지 않는다.
커스텀 리소스에 대한 자세한 내용은 커스텀 리소스 개념 가이드를 참고하길 바란다.
새로운 API와 자동화의 결합
사용자 정의 리소스 API와 컨트롤 루프의 조합을 오퍼레이터(operator) 패턴이라고 한다. 오퍼레이터 패턴은 특정 애플리케이션, 일반적으로 스테이트풀(stateful) 애플리케이션을 관리하는 데 사용된다. 이러한 사용자 정의 API 및 컨트롤 루프를 사용하여 스토리지나 정책과 같은 다른 리소스를 제어할 수도 있다.
빌트인 리소스 변경
사용자 정의 리소스를 추가하여 쿠버네티스 API를 확장하면 추가된 리소스는 항상 새로운 API 그룹에 속한다. 기존 API 그룹을 바꾸거나 변경할 수 없다.
API를 추가해도 기존 API(예: 파드)의 동작에 직접 영향을 미치지는 않지만 API 접근 익스텐션은 영향을 준다.
API 접근 익스텐션
요청이 쿠버네티스 API 서버에 도달하면 먼저 인증이 되고, 그런 다음 승인된 후 다양한 유형의 어드미션 컨트롤이 적용된다. 이 흐름에 대한 자세한 내용은 쿠버네티스 API에 대한 접근 제어를 참고하길 바란다.
이러한 각 단계는 익스텐션 포인트를 제공한다.
쿠버네티스에는 이를 지원하는 몇 가지 빌트인 인증 방법이 있다. 또한 인증 프록시 뒤에 있을 수 있으며 인증 헤더에서 원격 서비스로 토큰을 전송하여 확인할 수 있다(웹훅). 이러한 방법은 모두 인증 설명서에 설명되어 있다.
인증
인증은 모든 요청의 헤더 또는 인증서를 요청하는 클라이언트의 사용자 이름에 매핑한다.
쿠버네티스는 몇 가지 빌트인 인증 방법과 필요에 맞지 않는 경우 인증 웹훅 방법을 제공한다.
인가
인가는 특정 사용자가 API 리소스에서 읽고, 쓰고, 다른 작업을 수행할 수 있는지를 결정한다. 전체 리소스 레벨에서 작동하며 임의의 오브젝트 필드를 기준으로 구별하지 않는다. 빌트인 인증 옵션이 사용자의 요구를 충족시키지 못하면 인가 웹훅을 통해 사용자가 제공한 코드를 호출하여 인증 결정을 내릴 수 있다.
동적 어드미션 컨트롤
요청이 승인된 후, 쓰기 작업인 경우 어드미션 컨트롤 단계도 수행된다. 빌트인 단계 외에도 몇 가지 익스텐션이 있다.
- 이미지 정책 웹훅은 컨테이너에서 실행할 수 있는 이미지를 제한한다.
- 임의의 어드미션 컨트롤 결정을 내리기 위해 일반적인 어드미션 웹훅을 사용할 수 있다. 어드미션 웹훅은 생성 또는 업데이트를 거부할 수 있다.
인프라스트럭처 익스텐션
스토리지 플러그인
Flex Volumes을 사용하면
Kubelet이 바이너리 플러그인을 호출하여 볼륨을 마운트하도록 함으로써
빌트인 지원 없이 볼륨 유형을 마운트 할 수 있다.
FlexVolume은 쿠버네티스 v1.23부터 사용 중단(deprecated)되었다. Out-of-tree CSI 드라이버가 쿠버네티스에서 볼륨 드라이버를 작성할 때 추천하는 방식이다. 자세한 정보는 스토리지 업체를 위한 쿠버네티스 볼륨 플러그인 FAQ에서 찾을 수 있다.
장치 플러그인
장치 플러그인은 노드가 장치 플러그인을
통해 새로운 노드 리소스(CPU 및 메모리와 같은 빌트인 자원 외에)를
발견할 수 있게 해준다.
네트워크 플러그인
노드-레벨의 네트워크 플러그인
을 통해 다양한 네트워킹 패브릭을 지원할 수 있다.
스케줄러 익스텐션
스케줄러는 파드를 감시하고 파드를 노드에 할당하는 특수한 유형의
컨트롤러이다. 다른 쿠버네티스 컴포넌트를 계속 사용하면서
기본 스케줄러를 완전히 교체하거나,
여러 스케줄러를
동시에 실행할 수 있다.
이것은 중요한 부분이며, 거의 모든 쿠버네티스 사용자는 스케줄러를 수정할
필요가 없다는 것을 알게 된다.
스케줄러는 또한 웹훅 백엔드(스케줄러 익스텐션)가
파드에 대해 선택된 노드를 필터링하고 우선 순위를 지정할 수 있도록 하는
웹훅을
지원한다.
다음 내용
1 - 쿠버네티스 API 확장하기
1.1 - 커스텀 리소스
커스텀 리소스 는 쿠버네티스 API의 익스텐션이다. 이 페이지에서는 쿠버네티스 클러스터에
커스텀 리소스를 추가할 시기와 독립형 서비스를 사용하는 시기에 대해 설명한다. 커스텀 리소스를
추가하는 두 가지 방법과 이들 중에서 선택하는 방법에 대해 설명한다.
커스텀 리소스
리소스 는 쿠버네티스 API에서 특정 종류의
API 오브젝트 모음을 저장하는 엔드포인트이다. 예를 들어 빌트인 파드 리소스에는 파드 오브젝트 모음이 포함되어 있다.
커스텀 리소스 는 쿠버네티스 API의 익스텐션으로, 기본 쿠버네티스 설치에서 반드시
사용할 수 있는 것은 아니다. 이는 특정 쿠버네티스 설치에 수정이 가해졌음을 나타낸다. 그러나
많은 핵심 쿠버네티스 기능은 이제 커스텀 리소스를 사용하여 구축되어, 쿠버네티스를 더욱 모듈화한다.
동적 등록을 통해 실행 중인 클러스터에서 커스텀 리소스가 나타나거나 사라질 수 있으며
클러스터 관리자는 클러스터 자체와 독립적으로 커스텀 리소스를 업데이트 할 수 있다.
커스텀 리소스가 설치되면 사용자는 파드 와 같은 빌트인 리소스와 마찬가지로
kubectl을 사용하여 해당 오브젝트를 생성하고
접근할 수 있다.
커스텀 컨트롤러
자체적으로 커스텀 리소스를 사용하면 구조화된 데이터를 저장하고 검색할 수 있다.
커스텀 리소스를 커스텀 컨트롤러 와 결합하면, 커스텀 리소스가 진정한
선언적(declarative) API 를 제공하게 된다.
쿠버네티스 선언적 API는
책임의 분리를 강제한다. 사용자는 리소스의 의도한 상태를 선언한다.
쿠버네티스 컨트롤러는 쿠버네티스 오브젝트의 현재 상태가
선언한 의도한 상태에 동기화 되도록 한다.
이는 서버에 무엇을 해야할지 지시하는 명령적인 API와는 대조된다.
클러스터 라이프사이클과 관계없이 실행 중인 클러스터에 커스텀 컨트롤러를 배포하고
업데이트할 수 있다. 커스텀 컨트롤러는 모든 종류의 리소스와 함께 작동할 수 있지만
커스텀 리소스와 결합할 때 특히 효과적이다.
오퍼레이터 패턴은 사용자 정의
리소스와 커스텀 컨트롤러를 결합한다. 커스텀 컨트롤러를 사용하여 특정 애플리케이션에 대한 도메인 지식을
쿠버네티스 API의 익스텐션으로 인코딩할 수 있다.
쿠버네티스 클러스터에 커스텀 리소스를 추가해야 하나?
새로운 API를 생성할 때
쿠버네티스 클러스터 API와 생성한 API를 애그리게이트할 것인지
아니면 생성한 API를 독립적으로 유지할 것인지 고려하자.
| API 애그리게이트를 고려할 경우 |
독립 API를 고려할 경우 |
| API가 선언적이다. |
API가 선언적 모델에 맞지 않다. |
kubectl을 사용하여 새로운 타입을 읽고 쓸 수 있기를 원한다. |
kubectl 지원이 필요하지 않다. |
| 쿠버네티스 UI(예: 대시보드)에서 빌트인 타입과 함께 새로운 타입을 보길 원한다. |
쿠버네티스 UI 지원이 필요하지 않다. |
| 새로운 API를 개발 중이다. |
생성한 API를 제공하는 프로그램이 이미 있고 잘 작동하고 있다. |
| API 그룹 및 네임스페이스와 같은 REST 리소스 경로에 적용하는 쿠버네티스의 형식 제한을 기꺼이 수용한다. (API 개요를 참고한다.) |
이미 정의된 REST API와 호환되도록 특정 REST 경로가 있어야 한다. |
| 자체 리소스는 자연스럽게 클러스터 또는 클러스터의 네임스페이스로 범위가 지정된다. |
클러스터 또는 네임스페이스 범위의 리소스는 적합하지 않다. 특정 리소스 경로를 제어해야 한다. |
| 쿠버네티스 API 지원 기능을 재사용하려고 한다. |
이러한 기능이 필요하지 않다. |
선언적 API
선언적 API에서는 다음의 특성이 있다.
- API는 상대적으로 적은 수의 상대적으로 작은 오브젝트(리소스)로 구성된다.
- 오브젝트는 애플리케이션 또는 인프라의 구성을 정의한다.
- 오브젝트는 비교적 드물게 업데이트 된다.
- 사람이 종종 오브젝트를 읽고 쓸 필요가 있다.
- 오브젝트의 주요 작업은 CRUD-y(생성, 읽기, 업데이트 및 삭제)이다.
- 오브젝트 간 트랜잭션은 필요하지 않다. API는 정확한(exact) 상태가 아니라 의도한 상태를 나타낸다.
명령형 API는 선언적이지 않다.
자신의 API가 선언적이지 않을 수 있다는 징후는 다음과 같다.
- 클라이언트는 "이 작업을 수행한다"라고 말하고 완료되면 동기(synchronous) 응답을 받는다.
- 클라이언트는 "이 작업을 수행한다"라고 말한 다음 작업 ID를 다시 가져오고 별도의 오퍼레이션(operation) 오브젝트를 확인하여 요청의 완료 여부를 결정해야 한다.
- RPC(원격 프로시저 호출)에 대해 얘기한다.
- 대량의 데이터를 직접 저장한다. 예: > 오브젝트별 몇 kB 또는 > 1000개의 오브젝트.
- 높은 대역폭 접근(초당 10개의 지속적인 요청)이 필요하다.
- 최종 사용자 데이터(예: 이미지, PII 등) 또는 애플리케이션에서 처리한 기타 대규모 데이터를 저장한다.
- 오브젝트에 대한 자연스러운 조작은 CRUD-y가 아니다.
- API는 오브젝트로 쉽게 모델링되지 않는다.
- 작업 ID 또는 작업 오브젝트로 보류 중인 작업을 나타내도록 선택했다.
컨피그맵을 사용해야 하나, 커스텀 리소스를 사용해야 하나?
다음 중 하나에 해당하면 컨피그맵을 사용하자.
mysql.cnf 또는 pom.xml과 같이 잘 문서화된 기존 구성 파일 형식이 있다.- 전체 구성 파일을 컨피그맵의 하나의 키에 넣고 싶다.
- 구성 파일의 주요 용도는 클러스터의 파드에서 실행 중인 프로그램이 파일을 사용하여 자체 구성하는 것이다.
- 파일 사용자는 쿠버네티스 API가 아닌 파드의 환경 변수 또는 파드의 파일을 통해 사용하는 것을 선호한다.
- 파일이 업데이트될 때 디플로이먼트 등을 통해 롤링 업데이트를 수행하려고 한다.
참고: 민감한 데이터에는
시크릿을 사용하자. 이는 컨피그맵과 비슷하지만 더 안전한다.
다음 중 대부분이 적용되는 경우 커스텀 리소스(CRD 또는 애그리게이트 API(aggregated API))를 사용하자.
- 쿠버네티스 클라이언트 라이브러리 및 CLI를 사용하여 새 리소스를 만들고 업데이트하려고 한다.
kubectl 의 최상위 지원을 원한다. 예: kubectl get my-object object-name.- 새 오브젝트에 대한 업데이트를 감시한 다음 다른 오브젝트를 CRUD하거나 그 반대로 하는 새로운 자동화를 구축하려고 한다.
- 오브젝트의 업데이트를 처리하는 자동화를 작성하려고 한다.
.spec, .status 및 .metadata와 같은 쿠버네티스 API 규칙을 사용하려고 한다.- 제어된 리소스의 콜렉션 또는 다른 리소스의 요약에 대한 오브젝트가 되기를 원한다.
커스텀 리소스 추가
쿠버네티스는 클러스터에 커스텀 리소스를 추가하는 두 가지 방법을 제공한다.
- CRD는 간단하며 프로그래밍 없이 만들 수 있다.
- API 애그리게이션에는 프로그래밍이 필요하지만, 데이터 저장 방법 및 API 버전 간 변환과 같은 API 동작을 보다 강력하게 제어할 수 있다.
쿠버네티스는 다양한 사용자의 요구를 충족시키기 위해 이 두 가지 옵션을 제공하므로 사용의 용이성이나 유연성이 저하되지 않는다.
애그리게이트 API는 기본 API 서버 뒤에 있는 하위 API 서버이며 프록시 역할을 한다. 이 배치를 API 애그리게이션(AA)이라고 한다. 사용자에게는 쿠버네티스 API가 확장된 것으로 나타난다.
CRD를 사용하면 다른 API 서버를 추가하지 않고도 새로운 타입의 리소스를 생성할 수 있다. CRD를 사용하기 위해 API 애그리게이션을 이해할 필요는 없다.
설치 방법에 관계없이 새 리소스는 커스텀 리소스라고 하며 빌트인 쿠버네티스 리소스(파드 등)와 구별된다.
커스텀리소스데피니션
커스텀리소스데피니션
API 리소스를 사용하면 커스텀 리소스를 정의할 수 있다.
CRD 오브젝트를 정의하면 지정한 이름과 스키마를 사용하여 새 커스텀 리소스가 만들어진다.
쿠버네티스 API는 커스텀 리소스의 스토리지를 제공하고 처리한다.
CRD 오브젝트의 이름은 유효한
DNS 서브도메인 이름이어야 한다.
따라서 커스텀 리소스를 처리하기 위해 자신의 API 서버를 작성할 수 없지만
구현의 일반적인 특성으로 인해
API 서버 애그리게이션보다 유연성이 떨어진다.
새 커스텀 리소스를 등록하고 새 리소스 타입의 인스턴스에 대해 작업하고
컨트롤러를 사용하여 이벤트를 처리하는 방법에 대한 예제는
커스텀 컨트롤러 예제를 참고한다.
API 서버 애그리게이션
일반적으로 쿠버네티스 API의 각 리소스에는 REST 요청을 처리하고 오브젝트의 퍼시스턴트 스토리지를 관리하는 코드가 필요하다. 주요 쿠버네티스 API 서버는 파드 및 서비스 와 같은 빌트인 리소스를 처리하고, 일반적으로 CRD를 통해 커스텀 리소스를 처리할 수 있다.
애그리게이션 레이어를 사용하면 자체 API 서버를
작성하고 배포하여 커스텀 리소스에 대한 특수한 구현을 제공할 수 있다.
주(main) API 서버는 사용자의 커스텀 리소스에 대한 요청을 사용자의 자체 API 서버에 위임하여
모든 클라이언트가 사용할 수 있게 한다.
커스텀 리소스를 추가할 방법 선택
CRD는 사용하기가 더 쉽다. 애그리게이트 API가 더 유연하다. 자신의 요구에 가장 잘 맞는 방법을 선택하자.
일반적으로 CRD는 다음과 같은 경우에 적합하다.
- 필드가 몇 개 되지 않는다
- 회사 내에서 또는 소규모 오픈소스 프로젝트의 일부인(상용 제품이 아닌) 리소스를 사용하고 있다.
사용 편의성 비교
CRD는 애그리게이트 API보다 생성하기가 쉽다.
| CRD |
애그리게이트 API |
| 프로그래밍이 필요하지 않다. 사용자는 CRD 컨트롤러에 대한 모든 언어를 선택할 수 있다. |
프로그래밍하고 바이너리와 이미지를 빌드해야 한다. |
| 실행할 추가 서비스가 없다. CR은 API 서버에서 처리한다. |
추가 서비스를 생성하면 실패할 수 있다. |
| CRD가 생성된 후에는 지속적인 지원이 없다. 모든 버그 픽스는 일반적인 쿠버네티스 마스터 업그레이드의 일부로 선택된다. |
업스트림에서 버그 픽스를 주기적으로 선택하고 애그리게이트 API 서버를 다시 빌드하고 업데이트해야 할 수 있다. |
| 여러 버전의 API를 처리할 필요가 없다. 예를 들어, 이 리소스에 대한 클라이언트를 제어할 때 API와 동기화하여 업그레이드할 수 있다. |
인터넷에 공유할 익스텐션을 개발할 때와 같이 여러 버전의 API를 처리해야 한다. |
고급 기능 및 유연성
애그리게이트 API는 보다 고급 API 기능과 스토리지 레이어와 같은 다른 기능의 사용자 정의를 제공한다.
| 기능 |
설명 |
CRD |
애그리게이트 API |
| 유효성 검사 |
사용자가 오류를 방지하고 클라이언트와 독립적으로 API를 발전시킬 수 있도록 도와준다. 이러한 기능은 동시에 많은 클라이언트를 모두 업데이트할 수 없는 경우에 아주 유용하다. |
예. OpenAPI v3.0 유효성 검사를 사용하여 CRD에서 대부분의 유효성 검사를 지정할 수 있다. 웹훅 유효성 검사를 추가해서 다른 모든 유효성 검사를 지원한다. |
예, 임의의 유효성 검사를 지원한다. |
| 기본 설정 |
위를 참고하자. |
예, OpenAPI v3.0 유효성 검사의 default 키워드(1.17에서 GA) 또는 웹훅 변형(mutating)(이전 오브젝트의 etcd에서 읽을 때는 실행되지 않음)을 통해 지원한다. |
예 |
| 다중 버전 관리 |
두 가지 API 버전을 통해 동일한 오브젝트를 제공할 수 있다. 필드 이름 바꾸기와 같은 API 변경을 쉽게 할 수 있다. 클라이언트 버전을 제어하는 경우는 덜 중요하다. |
예 |
예 |
| 사용자 정의 스토리지 |
다른 성능 모드(예를 들어, 키-값 저장소 대신 시계열 데이터베이스)나 보안에 대한 격리(예를 들어, 암호화된 시크릿이나 다른 암호화) 기능을 가진 스토리지가 필요한 경우 |
아니오 |
예 |
| 사용자 정의 비즈니스 로직 |
오브젝트를 생성, 읽기, 업데이트 또는 삭제를 할 때 임의의 점검 또는 조치를 수행한다. |
예, 웹훅을 사용한다. |
예 |
| 서브리소스 크기 조정 |
HorizontalPodAutoscaler 및 PodDisruptionBudget과 같은 시스템이 새로운 리소스와 상호 작용할 수 있다. |
예 |
예 |
| 서브리소스 상태 |
사용자가 스펙 섹션을 작성하고 컨트롤러가 상태 섹션을 작성하는 세분화된 접근 제어를 허용한다. 커스텀 리소스 데이터 변형 시 오브젝트 생성을 증가시킨다(리소스에서 별도의 스펙과 상태 섹션 필요). |
예 |
예 |
| 기타 서브리소스 |
"logs" 또는 "exec"과 같은 CRUD 이외의 작업을 추가한다. |
아니오 |
예 |
| strategic-merge-patch |
새로운 엔드포인트는 Content-Type: application/strategic-merge-patch+json 형식의 PATCH를 지원한다. 로컬 및 서버 양쪽에서 수정할 수도 있는 오브젝트를 업데이트하는 데 유용하다. 자세한 내용은 "kubectl 패치를 사용한 API 오브젝트 업데이트"를 참고한다. |
아니오 |
예 |
| 프로토콜 버퍼 |
새로운 리소스는 프로토콜 버퍼를 사용하려는 클라이언트를 지원한다. |
아니오 |
예 |
| OpenAPI 스키마 |
서버에서 동적으로 가져올 수 있는 타입에 대한 OpenAPI(스웨거(swagger)) 스키마가 있는가? 허용된 필드만 설정하여 맞춤법이 틀린 필드 이름으로부터 사용자를 보호하는가? 타입이 적용되는가(즉, string 필드에 int를 넣지 않는가?) |
예, OpenAPI v3.0 유효성 검사를 기반으로 하는 스키마(1.16에서 GA) |
예 |
일반적인 기능
CRD 또는 AA를 통해 커스텀 리소스를 생성하면 쿠버네티스 플랫폼 외부에서 구현하는 것과 비교하여 API에 대한 많은 기능이 제공된다.
| 기능 |
설명 |
| CRUD |
새로운 엔드포인트는 HTTP 및 kubectl을 통해 CRUD 기본 작업을 지원한다. |
| 감시 |
새로운 엔드포인트는 HTTP를 통해 쿠버네티스 감시 작업을 지원한다. |
| 디스커버리 |
kubectl 및 대시보드와 같은 클라이언트는 리소스에 대해 목록, 표시 및 필드 수정 작업을 자동으로 제공한다. |
| json-patch |
새로운 엔드포인트는 Content-Type: application/json-patch+json 형식의 PATCH를 지원한다. |
| merge-patch |
새로운 엔드포인트는 Content-Type: application/merge-patch+json 형식의 PATCH를 지원한다. |
| HTTPS |
새로운 엔드포인트는 HTTPS를 사용한다. |
| 빌트인 인증 |
익스텐션에 대한 접근은 인증을 위해 기본 API 서버(애그리게이션 레이어)를 사용한다. |
| 빌트인 권한 부여 |
익스텐션에 접근하면 기본 API 서버(예: RBAC)에서 사용하는 권한을 재사용할 수 있다. |
| Finalizer |
외부 정리가 발생할 때까지 익스텐션 리소스의 삭제를 차단한다. |
| 어드미션 웹훅 |
생성/업데이트/삭제 작업 중에 기본값을 설정하고 익스텐션 리소스의 유효성 검사를 한다. |
| UI/CLI 디스플레이 |
Kubectl, 대시보드는 익스텐션 리소스를 표시할 수 있다. |
| 설정하지 않음(unset)과 비어있음(empty) |
클라이언트는 값이 없는 필드 중에서 설정되지 않은 필드를 구별할 수 있다. |
| 클라이언트 라이브러리 생성 |
쿠버네티스는 일반 클라이언트 라이브러리와 타입별 클라이언트 라이브러리를 생성하는 도구를 제공한다. |
| 레이블 및 어노테이션 |
공통 메타데이터는 핵심 및 커스텀 리소스를 수정하는 방법을 알고 있는 도구이다. |
커스텀 리소스 설치 준비
클러스터에 커스텀 리소스를 추가하기 전에 알아야 할 몇 가지 사항이 있다.
써드파티 코드 및 새로운 장애 포인트
CRD를 생성해도 새로운 장애 포인트(예를 들어, API 서버에서 장애를 유발하는 써드파티 코드가 실행됨)가 자동으로 추가되지는 않지만, 패키지(예: 차트(Charts)) 또는 기타 설치 번들에는 CRD 및 새로운 커스텀 리소스에 대한 비즈니스 로직을 구현하는 써드파티 코드의 디플로이먼트가 포함되는 경우가 종종 있다.
애그리게이트 API 서버를 설치하려면 항상 새 디플로이먼트를 실행해야 한다.
스토리지
커스텀 리소스는 컨피그맵과 동일한 방식으로 스토리지 공간을 사용한다. 너무 많은 커스텀 리소스를 생성하면 API 서버의 스토리지 공간이 과부하될 수 있다.
애그리게이트 API 서버는 기본 API 서버와 동일한 스토리지를 사용할 수 있으며 이 경우 동일한 경고가 적용된다.
인증, 권한 부여 및 감사
CRD는 항상 API 서버의 빌트인 리소스와 동일한 인증, 권한 부여 및 감사 로깅을 사용한다.
권한 부여에 RBAC를 사용하는 경우 대부분의 RBAC 역할은 새로운 리소스에 대한 접근 권한을 부여하지 않는다(클러스터 관리자 역할 또는 와일드 카드 규칙으로 생성된 역할 제외). 새로운 리소스에 대한 접근 권한을 명시적으로 부여해야 한다. CRD 및 애그리게이트 API는 종종 추가하는 타입에 대한 새로운 역할 정의와 함께 제공된다.
애그리게이트 API 서버는 기본 API 서버와 동일한 인증, 권한 부여 및 감사를 사용하거나 사용하지 않을 수 있다.
커스텀 리소스에 접근
쿠버네티스 클라이언트 라이브러리를 사용하여 커스텀 리소스에 접근할 수 있다. 모든 클라이언트 라이브러리가 커스텀 리소스를 지원하는 것은 아니다. Go 와 python 클라이언트 라이브러리가 지원한다.
커스텀 리소스를 추가하면 다음을 사용하여 접근할 수 있다.
kubectl- 쿠버네티스 동적 클라이언트
- 작성한 REST 클라이언트
- 쿠버네티스 클라이언트 생성 도구를 사용하여 생성된 클라이언트(하나를 생성하는 것은 고급 기능이지만, 일부 프로젝트는 CRD 또는 AA와 함께 클라이언트를 제공할 수 있다).
다음 내용
1.2 - 쿠버네티스 API 애그리게이션 레이어(aggregation layer)
애그리게이션 레이어는 코어 쿠버네티스 API가 제공하는 기능 이외에 더 많은 기능을 제공할 수 있도록 추가 API를 더해 쿠버네티스를 확장할 수 있게 해준다.
추가 API는 메트릭 서버와 같이 미리 만들어진 솔루션이거나 사용자가 직접 개발한 API일 수 있다.
애그리게이션 레이어는 kube-apiserver가 새로운 종류의 오브젝트를 인식하도록 하는 방법인 사용자 정의 리소스와는 다르다.
애그리게이션 레이어
애그리게이션 레이어는 kube-apiserver 프로세스 안에서 구동된다. 확장 리소스가 등록되기 전까지, 애그리게이션 레이어는 아무 일도 하지 않는다. API를 등록하기 위해서, 사용자는 쿠버네티스 API 내에서 URL 경로를 "요구하는(claim)" APIService 오브젝트를 추가해야 한다. 이때, 애그리게이션 레이어는 해당 API 경로(예: /apis/myextensions.mycompany.io/v1/...)로 전송되는 모든 것을 등록된 APIService로 프록시하게 된다.
APIService를 구현하는 가장 일반적인 방법은 클러스터 내에 실행되고 있는 파드에서 extension API server 를 실행하는 것이다. extension API server를 사용해서 클러스터의 리소스를 관리하는 경우 extension API server("extension-apiserver" 라고도 한다)는 일반적으로 하나 이상의 컨트롤러와 쌍을 이룬다. apiserver-builder 라이브러리는 extension API server와 연관된 컨틀로러에 대한 스켈레톤을 제공한다.
응답 레이턴시
Extension-apiserver는 kube-apiserver로 오가는 연결의 레이턴시가 낮아야 한다.
kube-apiserver로 부터의 디스커버리 요청은 왕복 레이턴시가 5초 이내여야 한다.
Extension API server가 레이턴시 요구 사항을 달성할 수 없는 경우 이를 충족할 수 있도록 변경하는 것을 고려한다.
다음 내용
대안으로, 어떻게 쿠버네티스 API를 커스텀 리소스 데피니션으로 확장하는지를 배워본다.
2 - 오퍼레이터(operator) 패턴
오퍼레이터(Operator)는
사용자 정의 리소스를
사용하여 애플리케이션 및 해당 컴포넌트를 관리하는 쿠버네티스의 소프트웨어 익스텐션이다. 오퍼레이터는
쿠버네티스 원칙, 특히 컨트롤 루프를 따른다.
동기 부여
오퍼레이터 패턴은 서비스 또는 서비스 셋을 관리하는 운영자의
주요 목표를 포착하는 것을 목표로 한다. 특정 애플리케이션 및
서비스를 돌보는 운영자는 시스템의 작동 방식, 배포 방법 및 문제가 있는 경우
대처 방법에 대해 깊이 알고 있다.
쿠버네티스에서 워크로드를 실행하는 사람들은 종종 반복 가능한 작업을 처리하기 위해
자동화를 사용하는 것을 좋아한다. 오퍼레이터 패턴은 쿠버네티스 자체가 제공하는 것 이상의
작업을 자동화하기 위해 코드를 작성하는 방법을 포착한다.
쿠버네티스의 오퍼레이터
쿠버네티스는 자동화를 위해 설계되었다. 기본적으로 쿠버네티스의 중추를 통해 많은
빌트인 자동화 기능을 사용할 수 있다. 쿠버네티스를 사용하여 워크로드 배포
및 실행을 자동화할 수 있고, 또한 쿠버네티스가 수행하는 방식을
자동화할 수 있다.
쿠버네티스의 오퍼레이터 패턴 개념을 통해 쿠버네티스 코드 자체를 수정하지 않고도 컨트롤러를 하나 이상의 사용자 정의 리소스(custom resource)에 연결하여 클러스터의 동작을 확장할 수 있다.
오퍼레이터는 사용자 정의 리소스의
컨트롤러 역할을 하는 쿠버네티스 API의 클라이언트이다.
오퍼레이터 예시
오퍼레이터를 사용하여 자동화할 수 있는 몇 가지 사항은 다음과 같다.
- 주문형 애플리케이션 배포
- 해당 애플리케이션의 상태를 백업하고 복원
- 데이터베이스 스키마 또는 추가 구성 설정과 같은 관련 변경 사항에 따른
애플리케이션 코드 업그레이드 처리
- 쿠버네티스 API를 지원하지 않는 애플리케이션에 서비스를
게시하여 검색을 지원
- 클러스터의 전체 또는 일부에서 장애를 시뮬레이션하여 가용성 테스트
- 내부 멤버 선출 절차없이 분산 애플리케이션의
리더를 선택
오퍼레이터의 모습을 더 자세하게 볼 수 있는 방법은 무엇인가? 예시는 다음과 같다.
- 클러스터에 구성할 수 있는 SampleDB라는 사용자 정의 리소스.
- 오퍼레이터의 컨트롤러 부분이 포함된 파드의 실행을
보장하는 디플로이먼트.
- 오퍼레이터 코드의 컨테이너 이미지.
- 컨트롤 플레인을 쿼리하여 어떤 SampleDB 리소스가 구성되어 있는지
알아내는 컨트롤러 코드.
- 오퍼레이터의 핵심은 API 서버에 구성된 리소스와 현재 상태를
일치시키는 방법을 알려주는 코드이다.
- 새 SampleDB를 추가하면 오퍼레이터는 퍼시스턴트볼륨클레임을
설정하여 내구성있는 데이터베이스 스토리지, SampleDB를 실행하는 스테이트풀셋 및
초기 구성을 처리하는 잡을 제공한다.
- SampleDB를 삭제하면 오퍼레이터는 스냅샷을 생성한 다음 스테이트풀셋과 볼륨도
제거되었는지 확인한다.
- 오퍼레이터는 정기적인 데이터베이스 백업도 관리한다. 오퍼레이터는 각 SampleDB
리소스에 대해 데이터베이스에 연결하고 백업을 수행할 수 있는 파드를 생성하는
시기를 결정한다. 이 파드는 데이터베이스 연결 세부 정보 및 자격 증명이 있는
컨피그맵 및 / 또는 시크릿에 의존한다.
- 오퍼레이터는 관리하는 리소스에 견고한 자동화를 제공하는 것을 목표로 하기 때문에
추가 지원 코드가 있다. 이 예제에서 코드는 데이터베이스가 이전 버전을 실행 중인지
확인하고, 업그레이드된 경우 이를 업그레이드하는
잡 오브젝트를 생성한다.
오퍼레이터 배포
오퍼레이터를 배포하는 가장 일반적인 방법은
커스텀 리소스 데피니션의 정의 및 연관된 컨트롤러를 클러스터에 추가하는 것이다.
컨테이너화된 애플리케이션을 실행하는 것처럼
컨트롤러는 일반적으로 컨트롤 플레인
외부에서 실행된다.
예를 들어 클러스터에서 컨트롤러를 디플로이먼트로 실행할 수 있다.
오퍼레이터 사용
오퍼레이터가 배포되면 오퍼레이터가 사용하는 리소스의 종류를 추가, 수정 또는
삭제하여 사용한다. 위의 예에 따라 오퍼레이터 자체에 대한
디플로이먼트를 설정한 후 다음을 수행한다.
kubectl get SampleDB # 구성된 데이터베이스 찾기
kubectl edit SampleDB/example-database # 일부 설정을 수동으로 변경하기
…이것으로 끝이다! 오퍼레이터는 변경 사항을 적용하고 기존 서비스를
양호한 상태로 유지한다.
자신만의 오퍼레이터 작성
에코시스템에 원하는 동작을 구현하는 오퍼레이터가 없다면
직접 코딩할 수 있다.
또한 쿠버네티스 API의 클라이언트
역할을 할 수 있는 모든 언어 / 런타임을 사용하여 오퍼레이터(즉, 컨트롤러)를 구현한다.
다음은 클라우드 네이티브 오퍼레이터를 작성하는 데 사용할 수 있는
몇 가지 라이브러리와 도구들이다.
참고:
이 섹션은 쿠버네티스에 필요한 기능을 제공하는 써드파티 프로젝트와 관련이 있다. 쿠버네티스 프로젝트 작성자는 써드파티 프로젝트에 책임이 없다. 이 페이지는
CNCF 웹사이트 가이드라인에 따라 프로젝트를 알파벳 순으로 나열한다. 이 목록에 프로젝트를 추가하려면 변경사항을 제출하기 전에
콘텐츠 가이드를 읽어본다.
다음 내용
3 - 컴퓨트, 스토리지 및 네트워킹 익스텐션
3.1 - 네트워크 플러그인
쿠버네티스 1.24 버전은 클러스터 네트워킹을 위해 컨테이너 네트워크 인터페이스(CNI) 플러그인을 지원한다.
클러스터와 호환되며 사용자의 요구 사항을 충족하는 CNI 플러그인을 사용해야 한다. 더 넓은 쿠버네티스 생태계에 다양한 플러그인이 존재한다(오픈소스 및 클로즈드 소스).
v0.4.0 이상의
CNI 스펙과 호환되는 CNI 플러그인을 사용해야 한다.
쿠버네티스 플러그인은
CNI 스펙 v1.0.0과 호환되는
플러그인의 사용을 권장한다(플러그인은 여러 스펙 버전과 호환 가능).
설치
CNI 플러그인은 쿠버네티스 네트워크 모델을 구현해야 한다. CRI는 자체 CNI 플러그인을 관리한다. 플러그인 사용 시 명심해야 할 두 가지 Kubelet 커맨드라인 파라미터가 있다.
cni-bin-dir: Kubelet은 시작할 때 플러그인에 대해 이 디렉터리를 검사한다.network-plugin: cni-bin-dir 에서 사용할 네트워크 플러그인. 플러그인 디렉터리에서 검색한 플러그인이 보고된 이름과 일치해야 한다. CNI 플러그인의 경우, 이는 "cni"이다.
네트워크 플러그인 요구 사항
파드 네트워킹을 구성하고 정리하기 위해 NetworkPlugin 인터페이스를 제공하는 것 외에도, 플러그인은 kube-proxy에 대한 특정 지원이 필요할 수 있다. iptables 프록시는 분명히 iptables에 의존하며, 플러그인은 컨테이너 트래픽이 iptables에 사용 가능하도록 해야 한다. 예를 들어, 플러그인이 컨테이너를 리눅스 브릿지에 연결하는 경우, 플러그인은 net/bridge/bridge-nf-call-iptables sysctl을 1 로 설정하여 iptables 프록시가 올바르게 작동하는지 확인해야 한다. 플러그인이 리눅스 브리지를 사용하지 않는 경우(그러나 Open vSwitch나 다른 메커니즘과 같은 기능을 사용함) 컨테이너 트래픽이 프록시에 대해 적절하게 라우팅되도록 해야 한다.
kubelet 네트워크 플러그인이 지정되지 않은 경우, 기본적으로 noop 플러그인이 사용되며, net/bridge/bridge-nf-call-iptables=1 을 설정하여 간단한 구성(브릿지가 있는 도커 등)이 iptables 프록시에서 올바르게 작동하도록 한다.
CNI
CNI 플러그인은 Kubelet에 --network-plugin=cni 커맨드라인 옵션을 전달하여 선택된다. Kubelet은 --cni-conf-dir(기본값은 /etc/cni/net.d)에서 파일을 읽고 해당 파일의 CNI 구성을 사용하여 각 파드의 네트워크를 설정한다. CNI 구성 파일은 CNI 명세와 일치해야 하며, 구성에서 참조하는 필수 CNI 플러그인은 --cni-bin-dir(기본값은 /opt/cni/bin)에 있어야 한다.
디렉터리에 여러 CNI 구성 파일이 있는 경우, kubelet은 이름별 알파벳 순으로 구성 파일을 사용한다.
구성 파일에 지정된 CNI 플러그인 외에도, 쿠버네티스는 최소 0.2.0 버전의 표준 CNI lo 플러그인이 필요하다.
hostPort 지원
CNI 네트워킹 플러그인은 hostPort 를 지원한다. CNI 플러그인 팀이 제공하는 공식 포트맵(portmap)
플러그인을 사용하거나 portMapping 기능이 있는 자체 플러그인을 사용할 수 있다.
hostPort 지원을 사용하려면, cni-conf-dir 에 portMappings capability 를 지정해야 한다.
예를 들면 다음과 같다.
{
"name": "k8s-pod-network",
"cniVersion": "0.3.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "127.0.0.1",
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "portmap",
"capabilities": {"portMappings": true}
}
]
}
트래픽 셰이핑 지원
실험적인 기능입니다
CNI 네트워킹 플러그인은 파드 수신 및 송신 트래픽 셰이핑도 지원한다. CNI 플러그인 팀에서 제공하는 공식 대역폭(bandwidth)
플러그인을 사용하거나 대역폭 제어 기능이 있는 자체 플러그인을 사용할 수 있다.
트래픽 셰이핑 지원을 활성화하려면, CNI 구성 파일 (기본값 /etc/cni/net.d)에 bandwidth 플러그인을
추가하고, 바이너리가 CNI 실행 파일 디렉터리(기본값: /opt/cni/bin)에 포함되어 있는지 확인한다.
{
"name": "k8s-pod-network",
"cniVersion": "0.3.0",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "127.0.0.1",
"ipam": {
"type": "host-local",
"subnet": "usePodCidr"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "bandwidth",
"capabilities": {"bandwidth": true}
}
]
}
이제 파드에 kubernetes.io/ingress-bandwidth 와 kubernetes.io/egress-bandwidth 어노테이션을 추가할 수 있다.
예를 들면 다음과 같다.
apiVersion: v1
kind: Pod
metadata:
annotations:
kubernetes.io/ingress-bandwidth: 1M
kubernetes.io/egress-bandwidth: 1M
...
용법 요약
--network-plugin=cni 는 --cni-bin-dir(기본값 /opt/cni/bin)에 있는 실제 CNI 플러그인 바이너리와 --cni-conf-dir(기본값 /etc/cni/net.d)에 있는 CNI 플러그인 구성과 함께 cni 네트워크 플러그인을 사용하도록 지정한다.
다음 내용
3.2 - 장치 플러그인
장치 플러그인을 사용하여 GPU, NIC, FPGA, 또는 비휘발성 주 메모리와 같이 공급 업체별 설정이 필요한 장치 또는 리소스를 클러스터에서 지원하도록 설정할 수 있다.
기능 상태: Kubernetes v1.10 [beta]
쿠버네티스는 시스템 하드웨어 리소스를 Kubelet에 알리는 데 사용할 수 있는
장치 플러그인 프레임워크를
제공한다.
공급 업체는 쿠버네티스 자체의 코드를 커스터마이징하는 대신, 수동 또는
데몬셋으로 배포하는 장치 플러그인을 구현할 수 있다.
대상이 되는 장치에는 GPU, 고성능 NIC, FPGA, InfiniBand 어댑터
및 공급 업체별 초기화 및 설정이 필요할 수 있는 기타 유사한 컴퓨팅 리소스가
포함된다.
장치 플러그인 등록
kubelet은 Registration gRPC 서비스를 노출시킨다.
service Registration {
rpc Register(RegisterRequest) returns (Empty) {}
}
장치 플러그인은 이 gRPC 서비스를 통해 kubelet에 자체 등록할 수 있다.
등록하는 동안, 장치 플러그인은 다음을 보내야 한다.
- 유닉스 소켓의 이름.
- 빌드된 장치 플러그인 API 버전.
- 알리려는
ResourceName. 여기서 ResourceName 은
확장된 리소스 네이밍 체계를
vendor-domain/resourcetype 의 형식으로 따라야 한다.
(예를 들어, NVIDIA GPU는 nvidia.com/gpu 로 알려진다.)
성공적으로 등록하고 나면, 장치 플러그인은 kubelet이 관리하는
장치 목록을 전송한 다음, kubelet은 kubelet 노드 상태 업데이트의 일부로
해당 자원을 API 서버에 알리는 역할을 한다.
예를 들어, 장치 플러그인이 kubelet에 hardware-vendor.example/foo 를 등록하고
노드에 두 개의 정상 장치를 보고하고 나면, 노드 상태가 업데이트되어
노드에 2개의 "Foo" 장치가 설치되어 사용 가능함을 알릴 수 있다.
그러고 나면, 사용자가 장치를 파드 스펙의 일부로 요청할 수
있다(container 참조).
확장 리소스를 요청하는 것은 다른 자원의 요청 및 제한을 관리하는 것과 비슷하지만,
다음과 같은 차이점이 존재한다.
- 확장된 리소스는 정수(integer) 형태만 지원되며 오버커밋(overcommit) 될 수 없다.
- 컨테이너간에 장치를 공유할 수 없다.
예제
쿠버네티스 클러스터가 특정 노드에서 hardware-vendor.example/foo 리소스를 알리는 장치 플러그인을 실행한다고
가정해 보자. 다음은 데모 워크로드를 실행하기 위해 이 리소스를 요청하는 파드의 예이다.
---
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
spec:
containers:
- name: demo-container-1
image: k8s.gcr.io/pause:2.0
resources:
limits:
hardware-vendor.example/foo: 2
#
# 이 파드는 2개의 hardware-vendor.example/foo 장치가 필요하며
# 해당 요구를 충족할 수 있는 노드에만
# 예약될 수 있다.
#
# 노드에 2개 이상의 사용 가능한 장치가 있는 경우
# 나머지는 다른 파드에서 사용할 수 있다.
장치 플러그인 구현
장치 플러그인의 일반적인 워크플로우에는 다음 단계가 포함된다.
-
초기화. 이 단계에서, 장치 플러그인은 공급 업체별 초기화 및 설정을 수행하여
장치가 준비 상태에 있는지 확인한다.
-
플러그인은 다음의 인터페이스를 구현하는 호스트 경로 /var/lib/kubelet/device-plugins/
아래에 유닉스 소켓과 함께 gRPC 서비스를 시작한다.
service DevicePlugin {
// GetDevicePluginOptions는 장치 관리자와 통신할 옵션을 반환한다.
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch는 장치 목록 스트림을 반환한다.
// 장치 상태가 변경되거나 장치가 사라질 때마다, ListAndWatch는
// 새 목록을 반환한다.
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// 컨테이너를 생성하는 동안 Allocate가 호출되어 장치
// 플러그인이 장치별 작업을 실행하고 Kubelet에 장치를
// 컨테이너에서 사용할 수 있도록 하는 단계를 지시할 수 있다.
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// GetPreferredAllocation은 사용 가능한 장치 목록에서 할당할
// 기본 장치 집합을 반환한다. 그 결과로 반환된 선호하는 할당은
// devicemanager가 궁극적으로 수행하는 할당이 되는 것을 보장하지
// 않는다. 가능한 경우 devicemanager가 정보에 입각한 할당 결정을
// 내릴 수 있도록 설계되었다.
rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
// PreStartContainer는 등록 단계에서 장치 플러그인에 의해 표시되면 각 컨테이너가
// 시작되기 전에 호출된다. 장치 플러그인은 장치를 컨테이너에서 사용할 수 있도록 하기 전에
// 장치 재설정과 같은 장치별 작업을 실행할 수 있다.
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
참고: GetPreferredAllocation() 또는 PreStartContainer() 에 대한 유용한 구현을
제공하기 위해 플러그인이 필요하지 않다. 이러한 호출(있는 경우) 중
사용할 수 있는 경우를 나타내는 플래그는 GetDevicePluginOptions()
호출에 의해 다시 전송된 DevicePluginOptions 메시지에 설정되어야 한다. kubelet 은
항상 GetDevicePluginOptions() 를 호출하여 사용할 수 있는
선택적 함수를 확인한 후 직접 호출한다.
-
플러그인은 호스트 경로 /var/lib/kubelet/device-plugins/kubelet.sock 에서
유닉스 소켓을 통해 kubelet에 직접 등록한다.
-
성공적으로 등록하고 나면, 장치 플러그인은 서빙(serving) 모드에서 실행되며, 그 동안 플러그인은 장치 상태를
모니터링하고 장치 상태 변경 시 kubelet에 다시 보고한다.
또한 gRPC 요청 Allocate 를 담당한다. Allocate 하는 동안, 장치 플러그인은
GPU 정리 또는 QRNG 초기화와 같은 장치별 준비를 수행할 수 있다.
작업이 성공하면, 장치 플러그인은 할당된 장치에 접근하기 위한 컨테이너 런타임 구성이 포함된
AllocateResponse 를 반환한다. kubelet은 이 정보를
컨테이너 런타임에 전달한다.
kubelet 재시작 처리
장치 플러그인은 일반적으로 kubelet의 재시작을 감지하고 새로운
kubelet 인스턴스에 자신을 다시 등록할 것으로 기대된다. 현재의 구현에서, 새 kubelet 인스턴스는 시작될 때
/var/lib/kubelet/device-plugins 아래에 있는 모든 기존의 유닉스 소켓을 삭제한다. 장치 플러그인은 유닉스 소켓의
삭제를 모니터링하고 이러한 이벤트가 발생하면 다시 자신을 등록할 수 있다.
장치 플러그인 배포
장치 플러그인을 데몬셋, 노드 운영 체제의 패키지
또는 수동으로 배포할 수 있다.
표준 디렉터리 /var/lib/kubelet/device-plugins 에는 특권을 가진 접근이 필요하므로,
장치 플러그인은 특권을 가진 보안 컨텍스트에서 실행해야 한다.
장치 플러그인을 데몬셋으로 배포하는 경우, 플러그인의
PodSpec에서
/var/lib/kubelet/device-plugins 를
볼륨으로 마운트해야 한다.
데몬셋 접근 방식을 선택하면 쿠버네티스를 사용하여 장치 플러그인의 파드를 노드에 배치하고,
장애 후 데몬 파드를 다시 시작하고, 업그레이드를 자동화할 수 있다.
API 호환성
쿠버네티스 장치 플러그인 지원은 베타 버전이다. 호환되지 않는 방식으로 안정화 전에 API가
변경될 수 있다. 프로젝트로서, 쿠버네티스는 장치 플러그인 개발자에게 다음 사항을 권장한다.
- 향후 릴리스에서 변경 사항을 확인하자.
- 이전/이후 버전과의 호환성을 위해 여러 버전의 장치 플러그인 API를 지원한다.
최신 장치 플러그인 API 버전의 쿠버네티스 릴리스로 업그레이드해야 하는 노드에서 DevicePlugins 기능을 활성화하고
장치 플러그인을 실행하는 경우, 이 노드를 업그레이드하기 전에
두 버전을 모두 지원하도록 장치 플러그인을 업그레이드한다. 이 방법을 사용하면
업그레이드 중에 장치 할당이 지속적으로 작동한다.
장치 플러그인 리소스 모니터링
기능 상태: Kubernetes v1.15 [beta]
장치 플러그인에서 제공하는 리소스를 모니터링하려면, 모니터링 에이전트가
노드에서 사용 중인 장치 셋을 검색하고 메트릭과 연관될 컨테이너를 설명하는
메타데이터를 얻을 수 있어야 한다. 장치 모니터링 에이전트에 의해 노출된
프로메테우스 지표는
쿠버네티스 Instrumentation 가이드라인을 따라
pod, namespace 및 container 프로메테우스 레이블을 사용하여 컨테이너를 식별해야 한다.
kubelet은 gRPC 서비스를 제공하여 사용 중인 장치를 검색하고, 이러한 장치에 대한 메타데이터를
제공한다.
// PodResourcesLister는 kubelet에서 제공하는 서비스로, 노드의 포드 및 컨테이너가
// 사용한 노드 리소스에 대한 정보를 제공한다.
service PodResourcesLister {
rpc List(ListPodResourcesRequest) returns (ListPodResourcesResponse) {}
rpc GetAllocatableResources(AllocatableResourcesRequest) returns (AllocatableResourcesResponse) {}
}
List gRPC 엔드포인트
List 엔드포인트는 실행 중인 파드의 리소스에 대한 정보를 제공하며,
독점적으로 할당된 CPU의 ID, 장치 플러그인에 의해 보고된 장치 ID,
이러한 장치가 할당된 NUMA 노드의 ID와 같은 세부 정보를 함께 제공한다. 또한, NUMA 기반 머신의 경우, 컨테이너를 위해 예약된 메모리와 hugepage에 대한 정보를 포함한다.
// ListPodResourcesResponse는 List 함수가 반환하는 응답이다.
message ListPodResourcesResponse {
repeated PodResources pod_resources = 1;
}
// PodResources에는 파드에 할당된 노드 리소스에 대한 정보가 포함된다.
message PodResources {
string name = 1;
string namespace = 2;
repeated ContainerResources containers = 3;
}
// ContainerResources는 컨테이너에 할당된 리소스에 대한 정보를 포함한다.
message ContainerResources {
string name = 1;
repeated ContainerDevices devices = 2;
repeated int64 cpu_ids = 3;
repeated ContainerMemory memory = 4;
}
// ContainerMemory는 컨테이너에 할당된 메모리와 hugepage에 대한 정보를 포함한다.
message ContainerMemory {
string memory_type = 1;
uint64 size = 2;
TopologyInfo topology = 3;
}
// 토폴로지는 리소스의 하드웨어 토폴로지를 설명한다.
message TopologyInfo {
repeated NUMANode nodes = 1;
}
// NUMA 노드의 NUMA 표현
message NUMANode {
int64 ID = 1;
}
// ContainerDevices는 컨테이너에 할당된 장치에 대한 정보를 포함한다.
message ContainerDevices {
string resource_name = 1;
repeated string device_ids = 2;
TopologyInfo topology = 3;
}
참고: List 엔드포인트의 ContainerResources 내부에 있는 cpu_ids은 특정 컨테이너에 할당된
독점 CPU들에 해당한다. 만약 공유 풀(shared pool)에 있는 CPU들을 확인(evaluate)하는 것이 목적이라면, 해당 List
엔드포인트는 다음에 설명된 것과 같이, GetAllocatableResources 엔드포인트와 함께 사용되어야
한다.
GetAllocatableResources를 호출하여 할당 가능한 모든 CPU 목록을 조회- 시스템의 모든
ContainerResources에서 GetCpuIds를 호출
GetAllocateableResources 호출에서 GetCpuIds 호출로 얻은 모든 CPU를 빼기
GetAllocatableResources gRPC 엔드포인트
기능 상태: Kubernetes v1.23 [beta]
GetAllocatableResources는 워커 노드에서 처음 사용할 수 있는 리소스에 대한 정보를 제공한다.
kubelet이 APIServer로 내보내는 것보다 더 많은 정보를 제공한다.
참고: GetAllocatableResources는
할당 가능(allocatable) 리소스를 확인(evaluate)하기 위해서만
사용해야 한다. 만약 목적이 free/unallocated 리소스를 확인하기 위한 것이라면
List() 엔드포인트와 함께 사용되어야 한다.
GetAllocableResources로 얻은 결과는 kubelet에
노출된 기본 리소스가 변경되지 않는 한 동일하게 유지된다. 이러한 변경은 드물지만, 발생하게 된다면
(예를 들면: hotplug/hotunplug, 장치 상태 변경) 클라이언트가
GetAlloctableResources 엔드포인트를
호출할 것으로 가정한다.
그러나 CPU 및/또는 메모리가 갱신된 경우
GetAllocateableResources 엔드포인트를 호출하는 것만으로는
충분하지 않으며, Kubelet을 다시 시작하여 올바른 리소스 용량과 할당 가능(allocatable) 리소스를 반영해야 한다.
// AllocatableResourcesResponses에는 kubelet이 알고 있는 모든 장치에 대한 정보가 포함된다.
message AllocatableResourcesResponse {
repeated ContainerDevices devices = 1;
repeated int64 cpu_ids = 2;
repeated ContainerMemory memory = 3;
}
쿠버네티스 v1.23부터, GetAllocatableResources가 기본으로 활성화된다.
이를 비활성화하려면 KubeletPodResourcesGetAllocatable 기능 게이트(feature gate)를
끄면 된다.
쿠버네티스 v1.23 이전 버전에서 이 기능을 활성화하려면 kubelet이 다음 플래그를 가지고 시작되어야 한다.
--feature-gates=KubeletPodResourcesGetAllocatable=true
ContainerDevices 는 장치가 어떤 NUMA 셀과 연관되는지를 선언하는 토폴로지 정보를 노출한다.
NUMA 셀은 불분명한(opaque) 정수 ID를 사용하여 식별되며, 이 값은
kubelet에 등록할 때 장치 플러그인이 보고하는 것과 일치한다.
gRPC 서비스는 /var/lib/kubelet/pod-resources/kubelet.sock 의 유닉스 소켓을 통해 제공된다.
장치 플러그인 리소스에 대한 모니터링 에이전트는 데몬 또는 데몬셋으로 배포할 수 있다.
표준 디렉터리 /var/lib/kubelet/pod-resources 에는 특권을 가진 접근이 필요하므로, 모니터링
에이전트는 특권을 가진 보안 컨텍스트에서 실행해야 한다. 장치 모니터링 에이전트가
데몬셋으로 실행 중인 경우, 해당 장치 모니터링 에이전트의 PodSpec에서
/var/lib/kubelet/pod-resources 를
볼륨으로 마운트해야 한다.
PodResourcesLister service 를 지원하려면 KubeletPodResources 기능 게이트를 활성화해야 한다.
이것은 쿠버네티스 1.15부터 기본으로 활성화되어 있으며, 쿠버네티스 1.20부터는 v1 상태이다.
토폴로지 관리자로 장치 플러그인 통합
기능 상태: Kubernetes v1.18 [beta]
토폴로지 관리자는 Kubelet 컴포넌트로, 리소스를 토폴로지 정렬 방식으로 조정할 수 있다. 이를 위해, 장치 플러그인 API가 TopologyInfo 구조체를 포함하도록 확장되었다.
message TopologyInfo {
repeated NUMANode nodes = 1;
}
message NUMANode {
int64 ID = 1;
}
토폴로지 관리자를 활용하려는 장치 플러그인은 장치 ID 및 장치의 정상 상태와 함께 장치 등록의 일부로 채워진 TopologyInfo 구조체를 다시 보낼 수 있다. 그런 다음 장치 관리자는 이 정보를 사용하여 토폴로지 관리자와 상의하고 리소스 할당 결정을 내린다.
TopologyInfo 는 nil(기본값) 또는 NUMA 노드 목록인 nodes 필드를 지원한다. 이를 통해 NUMA 노드에 걸쳐있을 수 있는 장치 플러그인을 게시할 수 있다.
장치 플러그인으로 장치에 대해 채워진 TopologyInfo 구조체의 예는 다음과 같다.
pluginapi.Device{ID: "25102017", Health: pluginapi.Healthy, Topology:&pluginapi.TopologyInfo{Nodes: []*pluginapi.NUMANode{&pluginapi.NUMANode{ID: 0,},}}}
장치 플러그인 예시
참고:
이 섹션은 쿠버네티스에 필요한 기능을 제공하는 써드파티 프로젝트와 관련이 있다. 쿠버네티스 프로젝트 작성자는 써드파티 프로젝트에 책임이 없다. 이 페이지는
CNCF 웹사이트 가이드라인에 따라 프로젝트를 알파벳 순으로 나열한다. 이 목록에 프로젝트를 추가하려면 변경사항을 제출하기 전에
콘텐츠 가이드를 읽어본다.
다음은 장치 플러그인 구현의 예이다.
다음 내용
4 - 서비스 카탈로그
서비스 카탈로그는 쿠버네티스 클러스터 내에서 실행되는 응용 프로그램이 클라우드 공급자가 제공하는 데이터 저장소 서비스와 같은 외부 관리 소프트웨어 제품을 쉽게 사용할 수 있도록하는 확장 API이다.
서비스 생성 또는 관리에 대한 자세한 지식 없이도 서비스 브로커를 통해 외부의 매니지드 서비스의 목록과 프로비전, 바인딩하는 방법을 제공한다.
오픈 서비스 브로커 API 명세에 정의된 서비스 브로커는 AWS, GCP 또는 Azure와 같은 타사 클라우드 공급자에 의해 제공되고 관리되는 매니지드 서비스의 세트에 대한 엔드포인트다.
매니지드 서비스의 예로 Microsoft Azure Cloud Queue, Amazon Simple Quere Service, Google Cloud Pub/Sub이 있으나 애플리케이션에서 사용할 수 있는 모든 소프트웨어 제품일 수 있다.
클러스터 오퍼레이터는 서비스 카탈로그를 사용하여 서비스 브로커가 제공하는 매니지드 서비스 목록을 탐색하거나 매니지드 서비스 인스턴스를 프로비저닝하고, 쿠버네티스 클러스터 내의 애플리케이션에서 사용할 수 있도록 바인딩할 수 있다.
유스케이스 예제
한 애플리케이션 개발자가 쿠버네티스 클러스터 내에서 실행되는 애플리케이션 중 일부로 메시지 큐를 사용하기를 원한다.
그러나 그러한 서비스에 대한 설정과 관리에는 부담이 따른다.
다행히 서비스 브로커를 통해 메시지 큐를 매니지드 서비스로 제공하는 클라우드 공급자가 있다.
클러스터 운영자는 서비스 카탈로그를 설정하고 이를 이용하여 클라우드 공급자의 서비스 브로커와 통신하여 메시지 큐 서비스의 인스턴스를 프로비저닝하고 쿠버네티스 클러스터 내의 애플리케이션에서 사용할 수 있게 한다.
따라서 애플리케이션 개발자는 메시지 큐의 세부 구현 또는 관리에 신경 쓸 필요가 없다.
애플리케이션은 메시지 큐에 서비스로 접속할 수 있다.
아키텍처
서비스 카탈로그는 오픈 서비스 브로커 API를 사용하여 쿠버네티스 API 서버가 초기 프로비저닝을 협상하고 애플리케이션이 매니지드 서비스를 사용하는데 필요한 자격 증명을 검색하는 중개자 역할을 하는 서비스 브로커와 통신한다.
이는 CRD 기반 아키텍처를 사용해서 구현되었다.

API 리소스
서비스 카탈로그는 servicecatalog.k8s.io API를 설치하고 다음 쿠버네티스 리소스를 제공한다.
ClusterServiceBroker: 서버 연결 세부 사항을 캡슐화한, 서비스 브로커의 클러스터 내부 대표.
이들은 클러스터 내에서 새로운 유형의 매니지드 서비스를 사용할 수 있도록 하려는 클러스터 운영자가 만들고 관리한다.ClusterServiceClass: 특정 서비스 브로커가 제공하는 매니지드 서비스.
새로운 ClusterServiceBroker 리소스가 클러스터에 추가되면 서비스 카탈로그 컨트롤러는 서비스 브로커에 연결해서 사용 가능한 매니지드 서비스 목록을 얻는다. 그 다음 각 매니지드 서비스에 해당하는 새로운 ClusterServiceClass 리소스를 만든다.ClusterServicePlan: 매니지드 서비스의 특별 요청. 예를 들어, 매니지드 서비스는 무료 혹은 유료 티어와 같이 사용 가능한 서로 다른 상품이 있거나, SSD 스토리지를 사용하거나 더 많은 리소스를 갖는 등 다른 구성 옵션을 가질 수 있다. ClusterServiceClass와 유사하게, 새로운 ClusterServiceBroker가 클러스터에 추가되면, 서비스 카탈로그는 각 매니지드 서비스에 사용 가능한 서비스 플랜에 해당하는 새로운 ClusterServicePlan 리소스를 작성한다.ServiceInstance: ClusterServiceClass의 프로비저닝된 인스턴스.
클러스터 운영자가 하나 이상의 클러스터 애플리케이션에서 사용할 수 있도록 매니지드 서비스의 특정 인스턴스를 사용하기 위해 생성한다.
새로운 ServiceInstance리소스가 생성되면, 서비스 카탈로그 컨트롤러는 해당 서비스 브로커에 연결하여 서비스 인스턴스를 프로비저닝하도록 지시한다.ServiceBinding: ServiceInstance에 대한 자격 증명에 액세스한다.
자신의 애플리케이션이 ServiceInstance를 사용하기를 원하는 클러스터 운영자가 이들을 생성한다.
서비스 카탈로그 컨트롤러는 생성 시 파드에 마운트될 수 있는 서비스 인스턴스에 대한 연결 세부 정보와 자격 증명이 포함된 쿠버네티스 '시크릿(secret)'을 생성한다.
인증
서비스 카탈로그는 다음의 인증 방법을 지원한다.
사용법
클러스터 운영자는 서비스 카탈로그 API 리소스를 사용하여 매니지드 서비스를 프로비저닝하여 쿠버네티스 클러스터 내에서 사용할 수 있게 한다. 관련 단계는 다음과 같다.
- 서비스 브로커에서 사용 가능한 매니지드 서비스와 서비스 플랜을 나열.
- 매니지드 서비스의 새 인스턴스 프로비저닝.
- 연결 자격 증명을 반환하는 매니지드 서비스에 바인딩.
- 연결 자격 증명을 애플리케이션에 매핑.
매니지드 서비스와 서비스 플랜 나열
먼저, 클러스터 운영자는 servicecatalog.k8s.io 그룹 내에 ClusterServiceBroker 리소스를 생성해야 한다. 이 리소스는 서비스 브로커 엔드포인트에 접근하는데 필요한 URL과 연결 세부 사항을 포함한다.
다음은 ClusterServiceBroker 리소스 예시이다.
apiVersion: servicecatalog.k8s.io/v1beta1
kind: ClusterServiceBroker
metadata:
name: cloud-broker
spec:
# 서비스 브로커의 엔드포인트를 가리킨다. (이 예시는 동작하지 않는 URL이다.)
url: https://servicebroker.somecloudprovider.com/v1alpha1/projects/service-catalog/brokers/default
#####
# bearer 토큰 정보 혹은 TLS용 caBundle과 같은
# 서비스 브로커와 통신하는데 사용될 수 있는 값을 여기에 추가할 수 있다.
#####
다음은 서비스 브로커에서 사용 가능한 매니지드 서비스와 플랜을 나열하는 단계를 설명하는 시퀀스 다이어그램이다.

-
ClusterServiceBroker 리소스가 서비스 카탈로그에 추가되면, 사용 가능한 서비스 목록에 대한 외부 서비스 브로커에 대한 호출을 발생시킨다.
-
서비스 브로커는 사용 가능한 매니지드 서비스 목록과 서비스 플랜 목록을 반환한다. 이 목록은 각각 로컬 ClusterServiceClass와 ClusterServicePlan 리소스로 캐시된다.
-
그런 다음 클러스터 운영자는 다음의 명령어를 사용하여 가용한 관리 서비스 목록을 얻을 수 있다.
kubectl get clusterserviceclasses -o=custom-columns=SERVICE\ NAME:.metadata.name,EXTERNAL\ NAME:.spec.externalName
아래와 같은 형태의 서비스 이름 목록이 출력된다.
SERVICE NAME EXTERNAL NAME
4f6e6cf6-ffdd-425f-a2c7-3c9258ad2468 cloud-provider-service
... ...
또한 다음의 명령어를 사용하여 가용한 서비스 플랜을 볼 수 있다.
kubectl get clusterserviceplans -o=custom-columns=PLAN\ NAME:.metadata.name,EXTERNAL\ NAME:.spec.externalName
아래와 같은 형태의 플랜 이름 목록이 출력된다.
PLAN NAME EXTERNAL NAME
86064792-7ea2-467b-af93-ac9694d96d52 service-plan-name
... ...
새 인스턴스 프로비저닝
클러스터 운영자는 ServiceInstance 리소스를 생성하여 새 인스턴스 프로비저닝을 시작할 수 있다.
다음은 ServiceInstance 리소스의 예시이다.
apiVersion: servicecatalog.k8s.io/v1beta1
kind: ServiceInstance
metadata:
name: cloud-queue-instance
namespace: cloud-apps
spec:
# 이전에 반환된 서비스 중 하나를 참조
clusterServiceClassExternalName: cloud-provider-service
clusterServicePlanExternalName: service-plan-name
#####
# 이곳에 서비스 브로커가 사용할 수 있는
# 파라미터를 추가할 수 있다.
#####
다음의 시퀀스 다이어그램은 매니지드 서비스의 새 인스턴스 프로비저닝과 관련된 일련의 단계를 보여준다.

ServiceInstance 리소스가 생성되면, 서비스 카탈로그는 서비스 인스턴스를 프로비저닝하기 위해 외부의 서비스 브로커 호출을 초기화한다.- 서비스 브로커는 새로운 매니지드 서비스 인스턴스를 생성하고 HTTP 응답을 리턴한다.
- 그 후 클러스터 운영자는 인스턴스 상태가 준비되었는지 점검할 수 있다.
매니지드 서비스에 바인딩
새 인스턴스가 프로비저닝된 후, 클러스터 운영자는 애플리케이션이 서비스를 사용하는데 필요한 자격 증명을 얻기 위해 매니지드 서비스에 바인드해야 한다. 이것은 ServiceBinding 리소스를 생성하는 것으로 이루어진다.
다음은 ServiceBinding 리소스의 예시다.
apiVersion: servicecatalog.k8s.io/v1beta1
kind: ServiceBinding
metadata:
name: cloud-queue-binding
namespace: cloud-apps
spec:
instanceRef:
name: cloud-queue-instance
#####
# 서비스 브로커가 사용할 수 있는 secretName, 서비스 어카운트 파라미터 등의
# 추가 정보를 여기에 추가할 수 있다.
#####
다음의 시퀀스 다이어그램은 매니지드 서비스 인스턴스에 바인딩하는 단계를 보여준다.

ServiceBinding이 생성된 이후, 서비스 카탈로그는 서비스 인스턴스와 바인딩하는데 필요한 정보를 요청하는 외부 서비스 브로커를 호출한다.- 서비스 브로커는 적절한 서비스 어카운트에 대한 애플리케이션 권한/역할을 활성화한다.
- 서비스 브로커는 매니지드 서비스 인스턴스에 연결하고 액세스하는데 필요한 정보를 리턴한다. 이는 제공자와 서비스에 특화되어 있으므로 서비스 프로바이더와 매니지드 서비스에 따라 다를 수 있다.
연결 자격 증명 매핑
바인딩 후 마지막 단계는 연결 자격 증명과 서비스 특화 정보를 애플리케이션에 매핑하는 것이다.
이런 정보는 클러스터의 애플리케이션이 액세스하여 매니지드 서비스와 직접 연결하는데 사용할 수 있는 시크릿으로 저장된다.

파드 구성 파일
이 매핑을 수행하는 한 가지 방법은 선언적 파드 구성을 사용하는 것이다.
다음 예시는 서비스 자격 증명을 애플리케이션에 매핑하는 방법을 설명한다. sa-key라는 키는 provider-cloud-key라는 볼륨에 저장되며, 애플리케이션은 이 볼륨을 /var/secrets/provider/key.json에 마운트한다. 환경 변수 PROVIDER_APPLICATION_CREDENTIALS는 마운트된 파일의 값에서 매핑된다.
...
spec:
volumes:
- name: provider-cloud-key
secret:
secretName: sa-key
containers:
...
volumeMounts:
- name: provider-cloud-key
mountPath: /var/secrets/provider
env:
- name: PROVIDER_APPLICATION_CREDENTIALS
value: "/var/secrets/provider/key.json"
다음 예시는 시크릿 값을 애플리케이션 환경 변수에 매핑하는 방법을 설명한다. 이 예시에서 메시지 큐 토픽 이름은 topic 라는 키의 provider-queue-credentials 시크릿에서 환경 변수 TOPIC에 매핑된다.
...
env:
- name: "TOPIC"
valueFrom:
secretKeyRef:
name: provider-queue-credentials
key: topic
다음 내용