Это многостраничный печатный вид этого раздела. Нажмите что бы печатать.
Обзор
- 1: Что такое Kubernetes
- 2: Компоненты Kubernetes
- 3: API Kubernetes
- 4: Работа с объектами Kubernetes
- 4.1: Изучение объектов Kubernetes
- 4.2: Управление объектами Kubernetes
- 4.3: Имена и идентификаторы объектов
- 4.4: Пространства имён
- 4.5: Метки и селекторы
- 4.6: Аннотации
- 4.7: Селекторы полей
- 4.8: Рекомендуемые метки
1 - Что такое Kubernetes
Эта страница посвящена краткому обзору Kubernetes.
Kubernetes — это портативная расширяемая платформа с открытым исходным кодом для управления контейнеризованными рабочими нагрузками и сервисами, которая облегчает как декларативную настройку, так и автоматизацию. У платформы есть большая, быстро растущая экосистема. Сервисы, поддержка и инструменты Kubernetes широко доступны.
Название Kubernetes происходит от греческого, что означает рулевой или штурман. Google открыл исходный код Kubernetes в 2014 году. Kubernetes основывается на десятилетнем опыте работы Google с масштабными рабочими нагрузками, в сочетании с лучшими в своем классе идеями и практиками сообщества.
История
Давайте вернемся назад и посмотрим, почему Kubernetes так полезен.

Традиционная эра развертывания: Ранее организации запускали приложения на физических серверах. Не было никакого способа определить границы ресурсов для приложений на физическом сервере, и это вызвало проблемы с распределением ресурсов. Например, если несколько приложений выполняются на физическом сервере, могут быть случаи, когда одно приложение будет занимать большую часть ресурсов, и в результате чего другие приложения будут работать хуже. Решением этого было запустить каждое приложение на другом физическом сервере. Но это не масштабировалось, поскольку ресурсы использовались не полностью, из-за чего организациям было накладно поддерживать множество физических серверов.
Эра виртуального развертывания: В качестве решения была представлена виртуализация. Она позволила запускать несколько виртуальных машин (ВМ) на одном физическом сервере. Виртуализация изолирует приложения между виртуальными машинами и обеспечивает определенный уровень безопасности, поскольку информация одного приложения не может быть свободно доступна другому приложению.
Виртуализация позволяет лучше использовать ресурсы на физическом сервере и обеспечивает лучшую масштабируемость, поскольку приложение можно легко добавить или обновить, кроме этого снижаются затраты на оборудование и многое другое. С помощью виртуализации можно превратить набор физических ресурсов в кластер одноразовых виртуальных машин.
Каждая виртуальная машина представляет собой полноценную машину, на которой выполняются все компоненты, включая собственную операционную систему, поверх виртуализированного оборудования.
Эра контейнеров: Контейнеры похожи на виртуальные машины, но у них есть свойства изоляции для совместного использования операционной системы (ОС) между приложениями. Поэтому контейнеры считаются легкими. Подобно виртуальной машине, контейнер имеет свою собственную файловую систему, процессор, память, пространство процесса и многое другое. Поскольку они не связаны с базовой инфраструктурой, они переносимы между облаками и дистрибутивами ОС.
Контейнеры стали популярными из-за таких дополнительных преимуществ как:
- Гибкое создание и развертывание приложений: простота и эффективность создания образа контейнера по сравнению с использованием образа виртуальной машины.
- Непрерывная разработка, интеграция и развертывание: обеспечивает надежную и частую сборку и развертывание образа контейнера с быстрым и простым откатом (благодаря неизменности образа).
- Разделение задач между Dev и Ops: создавайте образы контейнеров приложений во время сборки/релиза, а не во время развертывания, тем самым отделяя приложения от инфраструктуры.
- Наблюдаемость охватывает не только информацию и метрики на уровне ОС, но также информацию о работоспособности приложений и другие сигналы.
- Идентичная окружающая среда при разработке, тестировании и релизе: на ноутбуке работает так же, как и в облаке.
- Переносимость облачных и операционных систем: работает на Ubuntu, RHEL, CoreOS, on-prem, Google Kubernetes Engine и в любом другом месте.
- Управление, ориентированное на приложения: повышает уровень абстракции от запуска ОС на виртуальном оборудовании до запуска приложения в ОС с использованием логических ресурсов.
- Слабосвязанные, распределенные, гибкие, выделенные микросервисы: вместо монолитного стека на одной большой выделенной машине, приложения разбиты на более мелкие независимые части, которые можно динамически развертывать и управлять.
- Изоляция ресурсов: предсказуемая производительность приложения.
- Грамотное использование ресурсов: высокая эффективность и компактность.
Зачем вам Kubernetes и что он может сделать?
Контейнеры — отличный способ связать и запустить ваши приложения. В производственной среде необходимо управлять контейнерами, которые запускают приложения, и гарантировать отсутствие простоев. Например, если контейнер выходит из строя, необходимо запустить другой контейнер. Не было бы проще, если бы такое поведение обрабатывалось системой?
Вот тут Kubernetes приходит на помощь! Kubernetes дает вам фреймворк для гибкой работы распределенных систем. Он занимается масштабированием и обработкой ошибок в приложении, предоставляет шаблоны развертывания и многое другое. Например, Kubernetes может легко управлять канареечным развертыванием вашей системы.
Kubernetes предоставляет вам:
- Мониторинг сервисов и распределение нагрузки Kubernetes может обнаружить контейнер, используя имя DNS или собственный IP-адрес. Если трафик в контейнере высокий, Kubernetes может сбалансировать нагрузку и распределить сетевой трафик, чтобы развертывание было стабильным.
- Оркестрация хранилища Kubernetes позволяет вам автоматически смонтировать систему хранения по вашему выбору, такую как локальное хранилище, провайдеры общедоступного облака и многое другое.
- Автоматическое развертывание и откаты Используя Kubernetes можно описать желаемое состояние развернутых контейнеров и изменить фактическое состояние на желаемое. Например, вы можете автоматизировать Kubernetes на создание новых контейнеров для развертывания, удаления существующих контейнеров и распределения всех их ресурсов в новый контейнер.
- Автоматическое распределение нагрузки Вы предоставляете Kubernetes кластер узлов, который он может использовать для запуска контейнерных задач. Вы указываете Kubernetes, сколько ЦП и памяти (ОЗУ) требуется каждому контейнеру. Kubernetes может разместить контейнеры на ваших узлах так, чтобы наиболее эффективно использовать ресурсы.
- Самоконтроль Kubernetes перезапускает отказавшие контейнеры, заменяет и завершает работу контейнеров, которые не проходят определенную пользователем проверку работоспособности, и не показывает их клиентам, пока они не будут готовы к обслуживанию.
- Управление конфиденциальной информацией и конфигурацией Kubernetes может хранить и управлять конфиденциальной информацией, такой как пароли, OAuth-токены и ключи SSH. Вы можете развертывать и обновлять конфиденциальную информацию и конфигурацию приложения без изменений образов контейнеров и не раскрывая конфиденциальную информацию в конфигурации стека.
Чем Kubernetes не является
Kubernetes ― это не традиционная комплексная система PaaS (платформа как услуга). Поскольку Kubernetes работает на уровне контейнеров, а не на уровне оборудования, у него имеется определенные общеприменимые возможности, характерные для PaaS, такие как развертывание, масштабирование, балансировка нагрузки, ведение журналов и мониторинг. Тем не менее, Kubernetes это не монолитное решение, поэтому указанные возможности по умолчанию являются дополнительными и подключаемыми. У Kubernetes есть компоненты для создания платформы разработчика, но он сохраняет право выбора за пользователем и гибкость там, где это важно.
Kubernetes:
- Не ограничивает типы поддерживаемых приложений. Kubernetes стремится поддерживать широкий спектр рабочих нагрузок, включая те, у которых есть или отсутствует состояние, а также связанные с обработкой данных. Если приложение может работать в контейнере, оно должно отлично работать и в Kubernetes.
- Не развертывает исходный код и не собирает приложение. Рабочие процессы непрерывной интеграции, доставки и развертывания (CI/CD) определяются культурой и предпочтениями организации, а также техническими требованиями.
- Не предоставляет сервисы для приложения, такие как промежуточное программное обеспечение (например, очереди сообщений), платформы обработки данных (например, Spark), базы данных (например, MySQL), кеши или кластерные системы хранения (например, Ceph), как встроенные сервисы. Такие компоненты могут работать в Kubernetes и/или могут быть доступны для приложений, работающих в Kubernetes, через переносные механизмы, такие как Open Service Broker.
- Не включает решения для ведения журнала, мониторинга или оповещения. Он обеспечивает некоторые интеграции в качестве доказательства концепции и механизмы для сбора и экспорта метрик.
- Не указывает и не требует настройки языка/системы (например, Jsonnet). Он предоставляет декларативный API, который может быть нацелен на произвольные формы декларативных спецификаций.
- Не предоставляет и не принимает никаких комплексных систем конфигурации, технического обслуживания, управления или самовосстановления.
- Кроме того, Kubernetes — это не просто система оркестрации. Фактически, Kubernetes устраняет необходимость в этом. Техническое определение оркестрации — это выполнение определенного рабочего процесса: сначала сделай A, затем B, затем C. Напротив, Kubernetes содержит набор независимых, компонуемых процессов управления, которые непрерывно переводит текущее состояние к предполагаемому состоянию. Неважно, как добраться от А до С. Не требуется также централизованный контроль. Это делает систему более простой в использовании, более мощной, надежной, устойчивой и расширяемой.
Что дальше
- Изучите Компоненты Kubernetes
- Готовы начать?
2 - Компоненты Kubernetes
При развёртывании Kubernetes вы имеете дело с кластером.
Кластер Kubernetes cluster состоит из набор машин, так называемые узлы, которые запускают контейнеризированные приложения. Кластер имеет как минимум один рабочий узел.
В рабочих узлах размещены поды, являющиеся компонентами приложения. Плоскость управления управляет рабочими узлами и подами в кластере. В промышленных средах плоскость управления обычно запускается на нескольких компьютерах, а кластер, как правило, развёртывается на нескольких узлах, гарантируя отказоустойчивость и высокую надёжность.
На этой странице в общих чертах описывается различные компоненты, необходимые для работы кластера Kubernetes.
Ниже показана диаграмма кластера Kubernetes со всеми связанными компонентами.
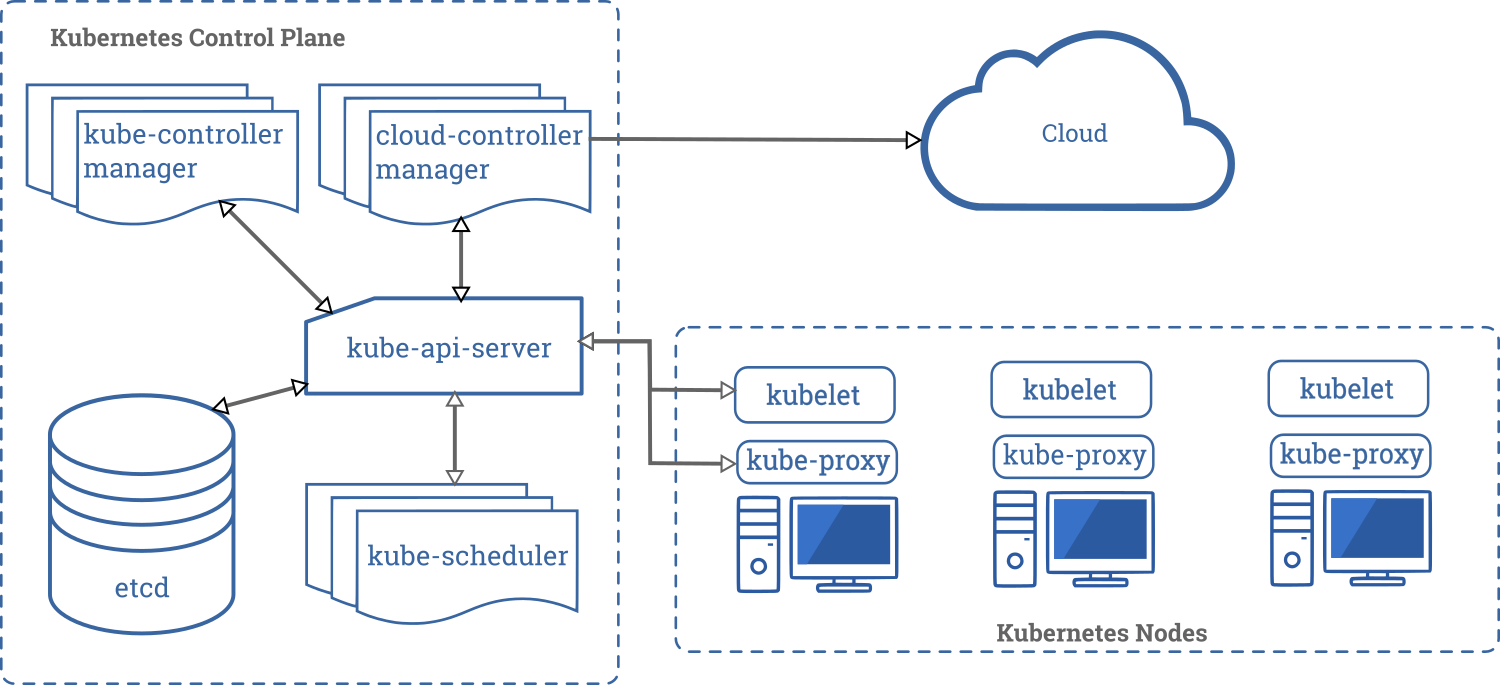
Плоскость управления компонентами
Компоненты панели управления отвечают за основные операции кластера (например, планирование), а также обрабатывают события кластера (например, запускают новый под, когда поле replicas развертывания не соответствует требуемому количеству реплик).
Компоненты панели управления могут быть запущены на любой машине в кластере. Однако для простоты сценарии настройки обычно запускают все компоненты панели управления на одном компьютере и в то же время не позволяют запускать пользовательские контейнеры на этом компьютере. Смотрите страницу Создание высоконадёжных кластеров для примера настройки нескольких ведущих виртуальных машин.
kube-apiserver
Сервер API — компонент Kubernetes панели управления, который представляет API Kubernetes. API-сервер — это клиентская часть панели управления Kubernetes
Основной реализацией API-сервера Kubernetes является kube-apiserver. kube-apiserver предназначен для горизонтального масштабирования, то есть развёртывание на несколько экземпляров. Вы можете запустить несколько экземпляров kube-apiserver и сбалансировать трафик между этими экземплярами.
etcd
Распределённое и высоконадёжное хранилище данных в формате "ключ-значение", которое используется как основное хранилище всех данных кластера в Kubernetes.
Если ваш кластер Kubernetes использует etcd в качестве основного хранилища, убедитесь, что у вас настроено резервное копирование данных.
Вы можете найти подробную информацию о etcd в официальной документации.
kube-scheduler
Компонент плоскости управления, который отслеживает созданные поды без привязанного узла и выбирает узел, на котором они должны работать.
При планировании развёртывания подов на узлах учитываются множество факторов, включая требования к ресурсам, ограничения, связанные с аппаратными/программными политиками, принадлежности (affinity) и непринадлежности (anti-affinity) узлов/подов, местонахождения данных, предельных сроков.
kube-controller-manager
Компонент Control Plane запускает процессы контроллера.
Вполне логично, что каждый контроллер в свою очередь представляет собой отдельный процесс, и для упрощения все такие процессы скомпилированы в один двоичный файл и выполняются в одном процессе.
Эти контроллеры включают:
- Контроллер узла (Node Controller): уведомляет и реагирует на сбои узла.
- Контроллер репликации (Replication Controller): поддерживает правильное количество подов для каждого объекта контроллера репликации в системе.
- Контроллер конечных точек (Endpoints Controller): заполняет объект конечных точек (Endpoints), то есть связывает сервисы (Services) и поды (Pods).
- Контроллеры учетных записей и токенов (Account & Token Controllers): создают стандартные учетные записи и токены доступа API для новых пространств имен.
cloud-controller-manager
cloud-controller-manager запускает контроллеры, которые взаимодействуют с основными облачными провайдерами. Двоичный файл cloud-controller-manager — это альфа-функциональность, появившиеся в Kubernetes 1.6.
cloud-controller-manager запускает только циклы контроллера, относящиеся к облачному провайдеру. Вам нужно отключить эти циклы контроллера в kube-controller-manager. Вы можете отключить циклы контроллера, установив флаг --cloud-provider со значением external при запуске kube-controller-manager.
С помощью cloud-controller-manager код как облачных провайдеров, так и самого Kubernetes может разрабатываться независимо друг от друга. В предыдущих версиях код ядра Kubernetes зависел от кода, предназначенного для функциональности облачных провайдеров. В будущих выпусках код, специфичный для облачных провайдеров, должен поддерживаться самим облачным провайдером и компоноваться с cloud-controller-manager во время запуска Kubernetes.
Следующие контроллеры зависят от облачных провайдеров:
- Контроллер узла (Node Controller): проверяет облачный провайдер, чтобы определить, был ли удален узел в облаке после того, как он перестал работать
- Контроллер маршрутов (Route Controller): настраивает маршруты в основной инфраструктуре облака
- Контроллер сервисов (Service Controller): создаёт, обновляет и удаляет балансировщики нагрузки облачного провайдера.
- Контроллер тома (Volume Controller): создаёт, присоединяет и монтирует тома, а также взаимодействует с облачным провайдером для оркестрации томов.
Компоненты узла
Компоненты узла работают на каждом узле, поддерживая работу подов и среды выполнения Kubernetes.
kubelet
Агент, работающий на каждом узле в кластере. Он следит за тем, чтобы контейнеры были запущены в поде.
Утилита kubelet принимает набор PodSpecs, и гарантирует работоспособность и исправность определённых в них контейнеров. Агент kubelet не отвечает за контейнеры, не созданные Kubernetes.
kube-proxy
kube-proxy — сетевой прокси, работающий на каждом узле в кластере, и реализующий часть концепции сервис.
kube-proxy конфигурирует правила сети на узлах. При помощи них разрешаются сетевые подключения к вашими подам изнутри и снаружи кластера.
kube-proxy использует уровень фильтрации пакетов в операционной системы, если он доступен. В противном случае, kube-proxy сам обрабатывает передачу сетевого трафика.
Среда выполнения контейнера
Среда выполнения контейнера — это программа, предназначенная для выполнения контейнеров.
Kubernetes поддерживает несколько сред для запуска контейнеров: Docker, containerd, CRI-O, и любая реализация Kubernetes CRI (Container Runtime Interface).
Дополнения
Дополнения используют ресурсы Kubernetes (DaemonSet, Deployment и т.д.) для расширения функциональности кластера. Поскольку дополнения охватывают весь кластер, ресурсы относятся к пространству имен kube-system.
Некоторые из дополнений описаны ниже; более подробный список доступных расширений вы можете найти на странице Дополнения.
DNS
Хотя прочие дополнения не являются строго обязательными, однако при этом у всех Kubernetes-кластеров должен быть кластерный DNS, так как многие примеры предполагают его наличие.
Кластерный DNS — это DNS-сервер наряду с другими DNS-серверами в вашем окружении, который обновляет DNS-записи для сервисов Kubernetes.
Контейнеры, запущенные посредством Kubernetes, автоматически включают этот DNS-сервер в свои DNS.
Веб-интерфейс (Dashboard)
Dashboard — это универсальный веб-интерфейс для кластеров Kubernetes. С помощью этой панели, пользователи могут управлять и устранять неполадки кластера и приложений, работающих в кластере.
Мониторинг ресурсов контейнера
Мониторинг ресурсов контейнера записывает общие метрики о контейнерах в виде временных рядов в центральной базе данных и предлагает пользовательский интерфейс для просмотра этих данных.
Логирование кластера
Механизм логирования кластера отвечает за сохранение логов контейнера в централизованном хранилище логов с возможностью их поиска/просмотра.
Что дальше
- Подробнее про узлы
- Подробнее про контроллеры
- Подробнее про kube-scheduler
- Официальная документация etcd
3 - API Kubernetes
Общие соглашения API описаны на странице соглашений API.
Конечные точки API, типы ресурсов и примеры описаны в справочнике API.
Удаленный доступ к API обсуждается в Controlling API Access doc.
API Kubernetes также служит основой декларативной схемы конфигурации системы. С помощью инструмента командной строки kubectl можно создавать, обновлять, удалять и получать API-объекты.
Kubernetes также сохраняет сериализованное состояние (в настоящее время в хранилище etcd) каждого API-ресурса.
Kubernetes как таковой состоит из множества компонентов, которые взаимодействуют друг с другом через собственные API.
Изменения в API
Исходя из нашего опыта, любая успешная система должна улучшаться и изменяться по мере появления новых сценариев использования или изменения существующих. Поэтому мы надеемся, что и API Kubernetes будет постоянно меняться и расширяться. Однако в течение продолжительного периода времени мы будем поддерживать хорошую обратную совместимость с существующими клиентами. В целом, новые ресурсы API и поля ресурсов будут добавляться часто. Удаление ресурсов или полей регулируются соответствующим процессом.
Определение совместимого изменения и методы изменения API подробно описаны в документе об изменениях API.
Определения OpenAPI и Swagger
Все детали API документируется с использованием OpenAPI.
Начиная с Kubernetes 1.10, API-сервер Kubernetes основывается на спецификации OpenAPI через конечную точку /openapi/v2.
Нужный формат устанавливается через HTTP-заголовки:
| Заголовок | Возможные значения |
|---|---|
| Accept | application/json, application/com.github.proto-openapi.spec.v2@v1.0+protobuf (по умолчанию заголовок Content-Type установлен в application/json с */*, допустимо также пропускать этот заголовок) |
| Accept-Encoding | gzip (можно не передавать этот заголовок) |
До версии 1.14 конечные точки с форматом (/swagger.json, /swagger-2.0.0.json, /swagger-2.0.0.pb-v1, /swagger-2.0.0.pb-v1.gz) предоставляли спецификацию OpenAPI в разных форматах. Эти конечные точки были объявлены устаревшими и удалены в Kubernetes 1.14.
Примеры получения спецификации OpenAPI:
| До 1.10 | С версии Kubernetes 1.10 |
|---|---|
| GET /swagger.json | GET /openapi/v2 Accept: application/json |
| GET /swagger-2.0.0.pb-v1 | GET /openapi/v2 Accept: application/com.github.proto-openapi.spec.v2@v1.0+protobuf |
| GET /swagger-2.0.0.pb-v1.gz | GET /openapi/v2 Accept: application/com.github.proto-openapi.spec.v2@v1.0+protobuf Accept-Encoding: gzip |
В Kubernetes реализован альтернативный формат сериализации API, основанный на Protobuf, который в первую очередь предназначен для взаимодействия внутри кластера. Описание этого формата можно найти в проектом решении, а IDL-файлы по каждой схемы — в пакетах Go, определяющих API-объекты.
До версии 1.14 apiserver Kubernetes также представлял API, который можно использовать для получения спецификации Swagger v1.2 для API Kubernetes по пути /swaggerapi. Эта конечная точка устарела и была удалена в Kubernetes 1.14
Версионирование API
Чтобы упростить удаления полей или изменение ресурсов, Kubernetes поддерживает несколько версий API, каждая из которых доступна по собственному пути, например, /api/v1 или /apis/extensions/v1beta1.
Мы выбрали версионирование API, а не конкретных ресурсов или полей, чтобы API отражал четкое и согласованное представление о системных ресурсах и их поведении, а также, чтобы разграничивать API, которые уже не поддерживаются и/или находятся в экспериментальной стадии. Схемы сериализации JSON и Protobuf следуют одним и тем же правилам по внесению изменений в схему, поэтому описание ниже охватывают оба эти формата.
Обратите внимание, что версионирование API и программное обеспечение косвенно связаны друг с другом. Предложение по версионированию API и новых выпусков описывает, как связаны между собой версии API с версиями программного обеспечения.
Разные версии API характеризуются разными уровнями стабильности и поддержки. Критерии каждого уровня более подробно описаны в документации изменений API. Ниже приводится краткое изложение:
- Альфа-версии:
- Названия версий включают надпись
alpha(например,v1alpha1). - Могут содержать баги. Включение такой функциональности может привести к ошибкам. По умолчанию она отключена.
- Поддержка функциональности может быть прекращена в любое время без какого-либо оповещения об этом.
- API может быть несовместим с более поздними версиями без упоминания об этом.
- Рекомендуется для использования только в тестировочных кластерах с коротким жизненным циклом из-за высокого риска наличия багов и отсутствия долгосрочной поддержки.
- Названия версий включают надпись
- Бета-версии:
- Названия версий включают надпись
beta(например,v2beta3). - Код хорошо протестирован. Активация этой функциональности — безопасно. Поэтому она включена по умолчанию.
- Поддержка функциональности в целом не будет прекращена, хотя кое-что может измениться.
- Схема и/или семантика объектов может стать несовместимой с более поздними бета-версиями или стабильными выпусками. Когда это случится, мы даем инструкции по миграции на следующую версию. Это обновление может включать удаление, редактирование и повторного создание API-объектов. Этот процесс может потребовать тщательного анализа. Кроме этого, это может привести к простою приложений, которые используют данную функциональность.
- Рекомендуется только для неосновного производственного использования из-за риска возникновения возможных несовместимых изменений с будущими версиями. Если у вас есть несколько кластеров, которые возможно обновить независимо, вы можете снять это ограничение.
- Пожалуйста, попробуйте в действии бета-версии функциональности и поделитесь своими впечатлениями! После того как функциональность выйдет из бета-версии, нам может быть нецелесообразно что-то дальше изменять.
- Названия версий включают надпись
- Стабильные версии:
- Имя версии
vX, гдеvX— целое число. - Стабильные версии функциональностей появятся в новых версиях.
- Имя версии
API-группы
Чтобы упростить расширение API Kubernetes, реализованы группы API.
Группа API указывается в пути REST и в поле apiVersion сериализованного объекта.
В настоящее время используется несколько API-групп:
-
Группа core, которая часто упоминается как устаревшая (legacy group), доступна по пути
/api/v1и используетapiVersion: v1. -
Именованные группы находятся в пути REST
/apis/$GROUP_NAME/$VERSIONи используютapiVersion: $GROUP_NAME/$VERSION(например,apiVersion: batch/v1). Полный список поддерживаемых групп API можно увидеть в справочнике API Kubernetes.
Есть два поддерживаемых пути к расширению API с помощью пользовательских ресурсов:
- CustomResourceDefinition для пользователей, которым нужен очень простой CRUD.
- Пользователи, которым нужна полная семантика API Kubernetes, могут реализовать собственный apiserver и использовать агрегатор для эффективной интеграции для клиентов.
Включение или отключение групп API
Некоторые ресурсы и группы API включены по умолчанию. Их можно включить или отключить, установив --runtime-config для apiserver. Флаг --runtime-config принимает значения через запятую. Например, чтобы отключить batch/v1, используйте --runtime-config=batch/v1=false, а чтобы включить batch/v2alpha1, используйте флаг --runtime-config=batch/v2alpha1.
Флаг набор пар ключ-значение, указанных через запятую, который описывает конфигурацию во время выполнения сервера.
--runtime-config.
Включение определённых ресурсов в группу extensions/v1beta1
DaemonSets, Deployments, StatefulSet, NetworkPolicies, PodSecurityPolicies и ReplicaSets в API-группе extensions/v1beta1 по умолчанию отключены.
Например: чтобы включить deployments и daemonsets, используйте флаг --runtime-config=extensions/v1beta1/deployments=true,extensions/v1beta1/daemonsets=true.
extensions/v1beta1 по историческим причинам.
4 - Работа с объектами Kubernetes
4.1 - Изучение объектов Kubernetes
На этой странице объясняется, как объекты Kubernetes представлены в API Kubernetes, и как их можно определить в формате .yaml.
Изучение объектов Kubernetes
Объекты Kubernetes — сущности, которые хранятся в Kubernetes. Kubernetes использует их для представления состояния кластера. В частности, они описывают следующую информацию:
- Какие контейнеризированные приложения запущены (и на каких узлах).
- Доступные ресурсы для этих приложений.
- Стратегии управления приложения, которые относятся, например, к перезапуску, обновлению или отказоустойчивости.
После создания объекта Kubernetes будет следить за существованием объекта. Создавая объект, вы таким образом указываете системе Kubernetes, какой должна быть рабочая нагрузка кластера; это требуемое состояние кластера.
Для работы с объектами Kubernetes – будь то создание, изменение или удаление — нужно использовать API Kubernetes. Например, при использовании CLI-инструмента kubectl, он обращается к API Kubernetes. С помощью одной из клиентской библиотеки вы также можете использовать API Kubernetes в собственных программах.
Спецификация и статус объекта
Почти в каждом объекте Kubernetes есть два вложенных поля-объекта, которые управляют конфигурацией объекта: spec и status.
При создании объекта в поле spec указывается требуемое состояние (описание характеристик, которые должны быть у объекта).
Поле status описывает текущее состояние объекта, которое создаётся и обновляется самим Kubernetes и его компонентами. Плоскость управления Kubernetes непрерывно управляет фактическим состоянием каждого объекта, чтобы оно соответствовало требуемому состоянию, которое было задано пользователем.
Например: Deployment — это объект Kubernetes, представляющий работающее приложение в кластере. При создании объекта Deployment вы можете указать в его поле spec, что хотите иметь три реплики приложения. Система Kubernetes получит спецификацию объекта Deployment и запустит три экземпляра приложения, таким образом обновит статус (состояние) объекта, чтобы он соответствовал заданной спецификации. В случае сбоя одного из экземпляров (это влечет за собой изменение состояние), Kubernetes обнаружит несоответствие между спецификацией и статусом и исправит его, т.е. активирует новый экземпляр вместо того, который вышел из строя.
Для получения дополнительной информации о спецификации объекта, статусе и метаданных смотрите документ с соглашениями API Kubernetes.
Описание объекта Kubernetes
При создании объекта в Kubernetes нужно передать спецификацию объекта, которая содержит требуемое состояние, а также основную информацию об объекте (например, его имя). Когда вы используете API Kubernetes для создания объекта (напрямую либо через kubectl), соответствующий API-запрос должен включать в теле запроса всю указанную информацию в JSON-формате. В большинстве случаев вы будете передавать kubectl эти данные, записанные в файле .yaml. Тогда инструмент kubectl преобразует их в формат JSON при выполнении запроса к API.
Ниже представлен пример .yaml-файла, в котором заданы обязательные поля и спецификация объекта, необходимая для объекта Deployment в Kubernetes:

apiVersion: apps/v1 # до версии 1.9.0 нужно использовать apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # запускает 2 пода, созданных по шаблону
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Один из способов создания объекта Deployment с помощью файла .yaml, показанного выше — использовать команду kubectl apply, которая принимает в качестве аргумента файл в формате .yaml. Например:
kubectl apply -f https://k8s.io/examples/application/deployment.yaml --record
Вывод будет примерно таким:
deployment.apps/nginx-deployment created
Обязательные поля
В файле .yaml создаваемого объекта Kubernetes необходимо указать значения для следующих полей:
apiVersion— используемая для создания объекта версия API Kuberneteskind— тип создаваемого объектаmetadata— данные, позволяющие идентифицировать объект (name,UIDи необязательное полеnamespace)spec— требуемое состояние объекта
Конкретный формат поля-объекта spec зависит от типа объекта Kubernetes и содержит вложенные поля, предназначенные только для используемого объекта. В справочнике API Kubernetes можно найти формат спецификации любого объекта Kubernetes.
Например, формат spec для объекта Pod находится в ядре PodSpec v1, а формат spec для Deployment — в DeploymentSpec v1 apps.
Что дальше
- Обзор API Kubernetes более подробно объясняет некоторые из API-концепций
- Познакомиться с наиболее важными и основными объектами в Kubernetes, например, с подами.
- Узнать подробнее про контролеры в Kubernetes
4.2 - Управление объектами Kubernetes
В инструменте командной строки kubectl есть несколько разных способов создания и управления объектами Kubernetes. На этой странице рассматриваются различные подходы. Изучите документацию по Kubectl для получения подробной информации по управлению объектами с помощью Kubectl.
Способы управления
| Способ управления | Область применения | Рекомендуемое окружение | Количество поддерживаемых авторов | Трудность изучения |
|---|---|---|---|---|
| Императивные команды | Активные объекты | Проекты в стадии разработки | 1+ | Низкая |
| Императивная конфигурация объекта | Отдельные файлы | Продакшен-проекты | 1 | Средняя |
| Декларативная конфигурация объекта | Директории или файлы | Продакшен-проекты | 1+ | Сложная |
Императивные команды
При использовании императивных команд пользователь работает непосредственно с активными (текущими) объектами в кластере. Пользователь указывает выполняемые операции команде kubectl в качестве аргументов или флагов.
Это самый простой способ начать или выполнять одноразовые задачи в кластере. Из-за того, что происходит работа с активными объектами напрямую, нет возможности посмотреть историю предыдущих конфигураций.
Примеры
Запустите экземпляр контейнера nginx, посредством создания объекта Deployment:
kubectl run nginx --image nginx
То же самое, но с другим синтаксисом:
kubectl create deployment nginx --image nginx
Плюсы и минусы
Преимущества по сравнению с конфигурацией объекта:
- Простые команды, которые легко выучить и запомнить.
- Для применения изменений в кластер нужно только выполнить команды.
Недостатки по сравнению с конфигурацией объекта:
- Команды не интегрированы с процессом проверки (обзора) изменений.
- У команд нет журнала с изменениями.
- Команды не дают источник записей, за исключением активных объектов.
- Команды не содержат шаблон для создания новых объектов.
Императивная конфигурация объекта
В случае использования императивной конфигурации объекта команде kubectl устанавливают действие (создание, замена и т.д.), необязательные флаги и как минимум одно имя файла. Файл должен содержать полное определение объекта в формате YAML или JSON.
Посмотрите Справочник API для получения более подробной информации про определения объекта.
replace заменяет существующую спецификацию новой (переданной), удаляя все изменения в объекте, которые не определены в конфигурационном файле. Такой подход не следует использовать для типов ресурсов, спецификации которых обновляются независимо от конфигурационного файла.
Например, поле externalIPs в сервисах типа LoadBalancer обновляется кластером независимо от конфигурации.
Примеры
Создать объекты, определенные в конфигурационном файле:
kubectl create -f nginx.yaml
Удалить объекты, определенные в двух конфигурационных файлах:
kubectl delete -f nginx.yaml -f redis.yaml
Обновить объекты, определенные в конфигурационном файле, перезаписав текущую конфигурацию:
kubectl replace -f nginx.yaml
Плюсы и минусы
Преимущества по сравнению с императивными командами:
- Конфигурация объекта может храниться в системе управления версиями, такой как Git.
- Конфигурация объекта может быть интегрирована с процессами проверки изменений и логирования.
- Конфигурация объекта предусматривает шаблон для создания новых объектов.
Недостатки по сравнению с императивными командами:
- Конфигурация объекта требует наличие общего представления об схеме объекта.
- Конфигурация объекта предусматривает написание файла YAML.
Преимущества по сравнению с декларативной конфигурацией объекта:
- Императивная конфигурация объекта проще и легче для понимания.
- Начиная с Kubernetes 1.5, конфигурация императивных объектов стала лучше и совершеннее.
Недостатки по сравнению с декларативной конфигурацией объекта:
- Императивная конфигурация объекта наилучшим образом работает с файлами, а не с директориями.
- Обновления текущих объектов должны быть описаны в файлах конфигурации, в противном случае они будут потеряны при следующей замене.
Декларативная конфигурация объекта
При использовании декларативной конфигурации объекта пользователь работает с локальными конфигурационными файлами объекта, при этом он не определяет операции, которые будут выполняться над этими файлами. Операции создания, обновления и удаления автоматически для каждого объекта определяются kubectl. Этот механизм позволяет работать с директориями, в ситуациях, когда для разных объектов может потребоваться выполнение других операций.
patch, чтобы записать только обнаруженные изменения, а не использовать для этого API-операцию replace, которая полностью заменяет конфигурацию объекта.
Примеры
Обработать все конфигурационные файлы объектов в директории configs и создать либо частично обновить активные объекты. Сначала можно выполнить diff, чтобы посмотреть, какие изменения будут внесены, и только после этого применить их:
kubectl diff -f configs/
kubectl apply -f configs/
Рекурсивная обработка директорий:
kubectl diff -R -f configs/
kubectl apply -R -f configs/
Плюсы и минусы
Преимущества по сравнению с императивной конфигурацией объекта:
- Изменения, внесенные непосредственно в активные объекты, будут сохранены, даже если они не отражены в конфигурационных файлах.
- Декларативная конфигурация объекта лучше работает с директориями и автоматически определяет тип операции (создание, частичное обновление, удаление) каждого объекта.
Недостатки по сравнению с императивной конфигурацией объекта:
- Декларативную конфигурацию объекта сложнее отладить и понять, когда можно получить неожиданные результаты.
- Частичные обновления с использованием различий приводит к сложным операциям слияния и исправления.
Что дальше
- Управление объектами Kubernetes с помощью императивных команд
- Управление объектами Kubernetes с помощью императивной конфигурации объекта
- Управление объектами Kubernetes с помощью декларативной конфигурации объекта
- Управление объектами Kubernetes с помощью Kustomize (декларативный способ)
- Справочник по командам Kubectl
- Документация Kubectl
- Справочник API Kubernetes
4.3 - Имена и идентификаторы объектов
Каждый объект в кластере имеет уникальное имя для конкретного типа ресурса. Кроме этого, у каждого объекта Kubernetes есть собственный уникальный идентификатор (UID) в пределах кластера.
Например, в одном и том же пространстве имён может быть только один Pod-объект с именем myapp-1234, и при этом существовать объект Deployment с этим же названием myapp-1234.
Для создания пользовательских неуникальных атрибутов у Kubernetes есть метки и аннотации.
Имена
Клиентская строка, предназначенная для ссылки на объект в URL-адресе ресурса, например /api/v1/pods/some-name.
Указанное имя может иметь только один объект определённого типа. Но если вы удалите этот объект, вы можете создать новый с таким же именем
Ниже перечислены три типа распространённых требований к именам ресурсов.
Имена поддоменов DNS
Большинству типов ресурсов нужно указать имя, используемое в качестве имени поддомена DNS в соответствии с RFC 1123. Соответственно, имя должно:
- содержать не более 253 символов
- иметь только строчные буквенно-цифровые символы, '-' или '.'
- начинаться с буквенно-цифрового символа
- заканчивается буквенно-цифровым символом
Имена меток DNS
Некоторые типы ресурсов должны соответствовать стандарту меток DNS, который описан в RFC 1123. Таким образом, имя должно:
- содержать не более 63 символов
- содержать только строчные буквенно-цифровые символы или '-'
- начинаться с буквенно-цифрового символа
- заканчивается буквенно-цифровым символом
Имена сегментов пути
Определённые имена типов ресурсов должны быть закодированы для использования в качестве сегмента пути. Проще говоря, имя не может быть "." или "..", а также не может содержать "/" или "%".
Пример файла манифеста пода nginx-demo.
apiVersion: v1
kind: Pod
metadata:
name: nginx-demo
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Уникальные идентификаторы
Уникальная строка, сгенерированная самим Kubernetes, для идентификации объектов.
У каждого объекта, созданного в течение всего периода работы кластера Kubernetes, есть собственный уникальный идентификатор (UID). Он предназначен для выяснения различий между событиями похожих сущностей.
Уникальные идентификатор (UID) в Kubernetes — это универсальные уникальные идентификаторы (известные также как Universally Unique IDentifier, сокращенно UUID). Эти идентификаторы стандартизированы под названием ISO/IEC 9834-8, а также как ITU-T X.667.
Что дальше
- Узнать подробнее про метки в Kubernetes.
- Посмотреть архитектуру идентификаторов и имён Kubernetes.
4.4 - Пространства имён
Kubernetes поддерживает несколько виртуальных кластеров в одном физическом кластере. Такие виртуальные кластеры называются пространствами имён.
Причины использования нескольких пространств имён
Пространства имён применяются в окружениях с многочисленными пользователями, распределенными по нескольким командам или проектам. Пространства имён не нужно создавать, если есть кластеры с небольшим количеством пользователей (например, десяток пользователей). Пространства имён имеет смысл использовать, когда необходима такая функциональность.
Пространства имён определяют область имён. Имена ресурсов должны быть уникальными в пределах одного и того же пространства имён. Пространства имён не могут быть вложенными, а каждый ресурс Kubernetes может находиться только в одном пространстве имён.
Пространства имён — это способ разделения ресурсов кластера между несколькими пользователями (с помощью квоты ресурсов).
По умолчанию в будущих версиях Kubernetes объекты в одном и том же пространстве имён будут иметь одинаковую политику контроля доступа.
Не нужно использовать пространства имён только для разделения слегка отличающихся ресурсов, например, в случае разных версий одного и того же приложения. Используйте метки, чтобы различать ресурсы в рамках одного пространства имён.
Использование пространств имён
Создание и удаление пространств имён описаны в руководстве администратора по пространствам имён.
Просмотр пространств имён
Используйте следующую команду, чтобы вывести список существующих пространств имён в кластере:
kubectl get namespace
NAME STATUS AGE
default Active 1d
kube-system Active 1d
kube-public Active 1d
По умолчанию в Kubernetes определены три пространства имён:
default— пространство имён по умолчанию для объектов без какого-либо другого пространства имён.kube-system— пространство имён для объектов, созданных Kuberneteskube-public— создаваемое автоматически пространство имён, которое доступно для чтения всем пользователям (включая также неаутентифицированных пользователей). Как правило, это пространство имён используется кластером, если некоторые ресурсы должны быть общедоступными для всего кластера. Главная особенность этого пространства имён — оно всего лишь соглашение, а не требование.
Определение пространства имён для отдельных команд
Используйте флаг --namespace, чтобы определить пространство имён только для текущего запроса.
Примеры:
kubectl run nginx --image=nginx --namespace=<insert-namespace-name-here>
kubectl get pods --namespace=<insert-namespace-name-here>
Определение пространства имён для всех команд
Можно определить пространство имён, которое должно использоваться для всех выполняемых команд kubectl в текущем контексте.
kubectl config set-context --current --namespace=<insert-namespace-name-here>
# Проверка
kubectl config view --minify | grep namespace:
Пространства имён и DNS
При создании сервиса создаётся соответствующая ему DNS-запись.
Эта запись вида <service-name>.<namespace-name>.svc.cluster.local означает, что если контейнер использует только <service-name>, то он будет локальным сервисом в пространстве имён. Это позволит применять одну и ту же конфигурацию в нескольких пространствах имен (например, development, staging и production). Если нужно обращаться к другим пространствам имён, то нужно использовать полностью определенное имя домена (FQDN).
Объекты без пространства имён
Большинство ресурсов Kubernetes (например, поды, сервисы, контроллеры репликации и другие) расположены в определённых пространствах имён. При этом сами ресурсы пространства имён не находятся ни в других пространствах имён. А такие низкоуровневые ресурсы, как узлы и persistentVolumes, не принадлежат ни одному пространству имён.
Чтобы посмотреть, какие ресурсы Kubernetes находятся в пространстве имён, а какие — нет, используйте следующие команды:
# Ресурсы в пространстве имён
kubectl api-resources --namespaced=true
# Ресурсы, не принадлежавшие ни одному пространству имён
kubectl api-resources --namespaced=false
Что дальше
- Узнать подробнее про создание нового пространства имён.
- Узнать подробнее про удаление пространства имён.
4.5 - Метки и селекторы
Метки — это пары ключ-значение, которые добавляются к объектам, как поды. Метки предназначены для идентификации атрибутов объектов, которые имеют значимость и важны для пользователей, но при этом не относятся напрямую к основной системе. Метки можно использовать для группировки и выбора подмножеств объектов. Метки могут быть добавлены к объектам во время создания и изменены в любое время после этого. Каждый объект может иметь набор меток в виде пары ключ-значение. Каждый ключ должен быть уникальным в рамках одного и того же объекта.
"metadata": {
"labels": {
"key1" : "value1",
"key2" : "value2"
}
}
Метки используются при получении и отслеживании объектов и в веб-панелях и CLI-инструментах. Любая неидентифицирующая информация должна быть записана в аннотации.
Причины использования
Метки позволяют пользователям гибко сопоставить их организационные структуры с системными объектами, не требуя от клиентов хранить эти соответствия.
Развертывания сервисов и процессы пакетной обработки часто являются многомерными сущностями (например, множество разделов или развертываний, несколько групп выпусков, несколько уровней приложения, несколько микросервисов на каждый уровень приложения). Для управления часто требуются сквозные операции, которые нарушают инкапсуляцию строго иерархических представлений, особенно жестких иерархий, определяемых инфраструктурой, а не пользователями.
Примеры меток:
"release" : "stable","release" : "canary""environment" : "dev","environment" : "qa","environment" : "production""tier" : "frontend","tier" : "backend","tier" : "cache""partition" : "customerA","partition" : "customerB""track" : "daily","track" : "weekly"
Это всего лишь примеры часто используемых меток; конечно, вы можете использовать свои собственные. Помните о том, что ключ метки должна быть уникальной в пределах одного объекта.
Синтаксис и набор символов
Метки представляют собой пары ключ-значение. Разрешенные ключи метки имеют два сегмента, разделённые слешем (/): префикс (необязательно) и имя. Сегмент имени обязателен и должен содержать не более 63 символов, среди которых могут быть буквенно-цифровые символы ([a-z0-9A-Z]), а также дефисы (-), знаки подчеркивания (_), точки (.). Префикс не обязателен, но он быть поддоменом DNS: набор меток DNS, разделенных точками (.), общей длиной не более 253 символов, за которыми следует слеш (/).
Если префикс не указан, ключ метки считается закрытым для пользователя. Компоненты автоматизированной системы (например, kube-scheduler, kube-controller-manager, kube-apiserver, kubectl или другие сторонние), которые добавляют метки к объектам пользователя, должны указывать префикс.
Префиксы kubernetes.io/ и k8s.io/ зарезервированы для использования основными компонентами Kubernetes.
Например, ниже представлен конфигурационный файл объекта Pod с двумя метками environment: production и app: nginx:
apiVersion: v1
kind: Pod
metadata:
name: label-demo
labels:
environment: production
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Селекторы меток
В отличие от имен и идентификаторов, метки не гарантируют уникальность. Поэтому мы предполагаем, что многие объекты будут иметь одинаковые метки.
С помощью селектора меток клиент/пользователь может идентифицировать набор объектов. Селектор меток — основное средство группировки в Kubernetes.
В настоящее время API поддерживает два типа селекторов: на равенстве и на наборе.
Селектор меток может состоять из нескольких условий, разделенных запятыми. В таком случае все условия должны быть выполнены, поэтому запятая-разделитель работает как логический оператор И (&&).
Работа пустых или неопределённых селекторов зависит от контекста. Типы API, которые использует селекторы, должны задокументировать это поведение.
||). Убедитесь, что синтаксис фильтрации правильно составлен.
Условие равенства
Условия равенства или неравенства позволяют отфильтровать объекты по ключам и значениям меток. Сопоставляемые объекты должны удовлетворять всем указанным условиям меток, хотя при этом у объектов также могут быть заданы другие метки.
Доступны три оператора: =,==,!=. Первые два означают равенство (и являются всего лишь синонимами), а последний оператор определяет неравенство. Например:
environment = production
tier != frontend
Первый пример выбирает все ресурсы с ключом environment, у которого значение указано production.
Последний получает все ресурсы с ключом tier без значения frontend, а также все ресурсы, в которых нет метки с ключом tier.
Используя оператор запятой можно совместить показанные два условия в одно, запросив ресурсы, в которых есть значение метки production и исключить frontend: environment=production,tier!=frontend.
С помощью условия равенства в объектах Pod можно указать, какие нужно выбрать ресурсы. Например, в примере ниже объект Pod выбирает узлы с меткой "accelerator=nvidia-tesla-p100".
apiVersion: v1
kind: Pod
metadata:
name: cuda-test
spec:
containers:
- name: cuda-test
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-p100
Условие набора
Условие меток на основе набора фильтрует ключи в соответствии с набором значений. Поддерживаются три вида операторов: in, notin и exists (только идентификатор ключа). Например:
environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
В первом примере выбираются все ресурсы с ключом environment и значением production или qa.
Во втором примере выбираются все ресурсы с ключом tier и любыми значениями, кроме frontend и backend, а также все ресурсы без меток с ключом tier.
Третий пример выбирает все ресурсы, включая метку с ключом partition (с любым значением).
В четвертом примере выбираются все ресурсы без метки с ключом partition (с любым значением).
Как и логический оператор И работает разделитель в виде запятой. Таким образом, фильтрация ресурсов по ключу partition (вне зависимости от значения) и ключу environment с любым значением, кроме qa, можно получить с помощью следующего выражения: partition,environment notin (qa).
Селектор меток на основе набора — основная форма равенства, поскольку environment=production то же самое, что и environment in (production); аналогично, оператор != соответствует notin.
Условия набора могут использоваться одновременно с условия равенства. Например, так: partition in (customerA, customerB),environment!=qa.
API
Фильтрация LIST и WATCH
Операции LIST и WATCH могут использовать параметр запроса, чтобы указать селекторы меток фильтрации наборов объектов. Есть поддержка обоих условий (строка запроса URL ниже показывается в исходном виде):
- Условия на основе равенства:
?labelSelector=environment%3Dproduction,tier%3Dfrontend - Условия на основе набора:
?labelSelector=environment+in+%28production%2Cqa%29%2Ctier+in+%28frontend%29
Указанные выше формы селектора меток можно использовать для просмотра или отслеживания ресурсов через REST-клиент. Например, apiserver с kubectl, который использует условие равенства:
kubectl get pods -l environment=production,tier=frontend
Либо используя условия на основе набора:
kubectl get pods -l 'environment in (production),tier in (frontend)'
Как уже показывалось, условия набора дают больше возможностей. Например, в них можно использовать подобие оператора И:
kubectl get pods -l 'environment in (production, qa)'
Либо можно воспользоваться исключающим сопоставлением с помощью оператора exists:
kubectl get pods -l 'environment,environment notin (frontend)'
Установка ссылок в API-объекты
Некоторые объекты Kubernetes, такие как services и replicationcontrollers, также используют селекторы меток для ссылки на наборы из других ресурсов, например, подов.
Service и ReplicationController
Набор подов, на которые указывает service, определяется через селектор меток. Аналогичным образом, количество подов, которыми должен управлять replicationcontroller, также формируются с использованием селектора меток.
Селекторы меток для обоих объектов записываются в словарях файлов формата json и yaml, при этом поддерживаются только селекторы с условием равенства:
"selector": {
"component" : "redis",
}
Или:
selector:
component: redis
Этот селектор (как в формате json, так и в yaml) эквивалентен component=redis или component in (redis).
Ресурсы, поддерживающие условия набора
Новые ресурсы, такие как Job, Deployment, ReplicaSet и DaemonSet, также поддерживают условия набора.
selector:
matchLabels:
component: redis
matchExpressions:
- {key: tier, operator: In, values: [cache]}
- {key: environment, operator: NotIn, values: [dev]}
matchLabels — словарь пар {key,value}. Каждая пара {key,value} в словаре matchLabels эквивалентна элементу matchExpressions, где поле key — "key", поле operator — "In", а массив values содержит только "value".
matchExpressions представляет собой список условий селектора пода. В качестве операторов могут быть In, NotIn, Exists и DoesNotExist. В случае использования In и NotIn должны заданы непустые значения. Все условия, как для matchLabels, так и для matchExpressions, объединяются с помощью логического И, поэтому при выборке объектов все они должны быть выполнены.
Выбор наборов узлов
Один из вариантов использования меток — возможность выбора набора узлов, в которых может быть развернут под. Смотрите документацию про выбор узлов, чтобы получить дополнительную информацию.
4.6 - Аннотации
Аннотации Kubernetes можно использовать для добавления собственных метаданных к объектам. Такие клиенты, как инструменты и библиотеки, могут получить эти метаданные.
Добавление метаданных к объектам
Вы можете использовать метки или аннотации для добавления метаданных к объектам Kubernetes. Метки можно использовать для выбора объектов и для поиска коллекций объектов, которые соответствуют определенным условиям. В отличие от них аннотации не используются для идентификации и выбора объектов. Метаданные в аннотации могут быть маленькими или большими, структурированными или неструктурированными, кроме этого они включать символы, которые не разрешены в метках.
Аннотации, как и метки, являются коллекциями с наборами пар ключ-значение:
"metadata": {
"annotations": {
"key1" : "value1",
"key2" : "value2"
}
}
Некоторые примеры информации, которая может быть в аннотациях:
-
Поля, управляемые декларативным уровнем конфигурации. Добавление этих полей в виде аннотаций позволяет отличать их от значений по умолчанию, установленных клиентами или серверами, а также от автоматически сгенерированных полей и полей, заданных системами автоматического масштабирования.
-
Информация о сборке, выпуске или образе, например, метка времени, идентификаторы выпуска, ветка git, номера PR, хеши образов и адрес реестра.
-
Ссылки на репозитории логирования, мониторинга, аналитики или аудита.
-
Информация о клиентской библиотеке или инструменте, которая может использоваться при отладке (например, имя, версия и информация о сборке).
-
Информация об источнике пользователя или инструмента/системы, например, URL-адреса связанных объектов из других компонентов экосистемы.
-
Небольшие метаданные развертывания (например, конфигурация или контрольные точки).
-
Номера телефонов или пейджеров ответственных лиц или записи в справочнике, в которых можно найти нужную информацию, например, сайт группы.
-
Инструкции от конечных пользователей по исправлению работы или использования нестандартной функциональности.
Вместо использования аннотаций, вы можете сохранить такого рода информацию во внешней базе данных или директории, хотя это усложнило бы создание общих клиентских библиотек и инструментов развертывания, управления, самодиагностики и т.д.
Синтаксис и набор символов
Аннотации представляют собой пары ключ-значение. Разрешенные ключи аннотации имеют два сегмента, разделённые слешем (/): префикс (необязательно) и имя. Сегмент имени обязателен и должен содержать не более 63 символов, среди которых могут быть буквенно-цифровые символы([a-z0-9A-Z]), а также дефисы (-), знаки подчеркивания (_), точки (.). Префикс не обязателен, но он быть поддоменом DNS: набор меток DNS, разделенных точками (.), общей длиной не более 253 символов, за которыми следует слеш (/).
Если префикс не указан, ключ аннотации считается закрытым для пользователя. Компоненты автоматизированной системы (например, kube-scheduler, kube-controller-manager, kube-apiserver, kubectl или другие сторонние), которые добавляют аннотации к объектам пользователя, должны указывать префикс.
Префиксы kubernetes.io/ и k8s.io/ зарезервированы для использования основными компонентами Kubernetes.
Например, ниже представлен конфигурационный файл объекта Pod с аннотацией imageregistry: https://hub.docker.com/:
apiVersion: v1
kind: Pod
metadata:
name: annotations-demo
annotations:
imageregistry: "https://hub.docker.com/"
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Что дальше
Узнать подробнее про метки и селекторы.
4.7 - Селекторы полей
Селекторы полей позволяют выбирать ресурсы Kubernetes, исходя из значения одного или нескольких полей ресурсов. Ниже приведены несколько примеров запросов селекторов полей:
metadata.name=my-servicemetadata.namespace!=defaultstatus.phase=Pending
Следующая команда kubectl выбирает все Pod-объекты, в которых значение поля status.phase равно Running:
kubectl get pods --field-selector status.phase=Running
По сути, селекторы полей являются фильтрами ресурсов. По умолчанию нет установленных селекторов/фильтров, поэтому выбираются ресурсы всех типов. Это означает, что два запроса kubectl ниже одинаковы:
kubectl get pods
kubectl get pods --field-selector ""
Поддерживаемые поля
Доступные селекторы полей зависят от типа ресурса Kubernetes. У всех типов ресурсов есть поля metadata.name и metadata.namespace. При использовании несуществующего селекторов полей приведёт к возникновению ошибки. Например:
kubectl get ingress --field-selector foo.bar=baz
Error from server (BadRequest): Unable to find "ingresses" that match label selector "", field selector "foo.bar=baz": "foo.bar" is not a known field selector: only "metadata.name", "metadata.namespace"
Поддерживаемые операторы
Можно использовать операторы =, == и != в селекторах полей (= и == — синонимы). Например, следующая команда kubectl выбирает все сервисы Kubernetes, не принадлежавшие пространству имен default:
kubectl get services --all-namespaces --field-selector metadata.namespace!=default
Составные селекторы
Аналогично метки и другим селекторам, несколько селекторы полей могут быть объединены через запятую. Приведенная ниже команда kubectl выбирает все Pod-объекты, у которых значение поле status.phase, отличное от Running, а поле spec.restartPolicy имеет значение Always:
kubectl get pods --field-selector=status.phase!=Running,spec.restartPolicy=Always
Множественные типы ресурсов
Можно использовать селекторы полей с несколькими типами ресурсов одновременно. Команда kubectl выбирает все объекты StatefulSet и Services, не включенные в пространство имен default:
kubectl get statefulsets,services --all-namespaces --field-selector metadata.namespace!=default
4.8 - Рекомендуемые метки
Вы можете визуализировать и управлять объектами Kubernetes не только с помощью kubectl и панели управления. С помощью единого набора меток можно единообразно описывать объекты, что позволяет инструментам согласованно работать между собой.
В дополнение к существующим инструментам, рекомендуемый набор меток описывают приложения в том виде, в котором они могут быть получены.
Метаданные сосредоточены на понятии приложение. Kubernetes — это не платформа как услуга (PaaS), поэтому не закрепляет формальное понятие приложения. Вместо этого приложения являются неформальными и описываются через метаданные. Определение приложения довольно расплывчатое.
Общие метки и аннотации используют один и тот же префикс: app.kubernetes.io. Метки без префикса являются приватными для пользователей. Совместно используемый префикс гарантирует, что общие метки не будут влиять на пользовательские метки.
Метки
Чтобы извлечь максимум пользы от использования таких меток, они должны добавляться к каждому ресурсному объекту.
| Ключ | Описание | Пример | Тип |
|---|---|---|---|
app.kubernetes.io/name |
Имя приложения | mysql |
string |
app.kubernetes.io/instance |
Уникальное имя экземпляра приложения | wordpress-abcxzy |
string |
app.kubernetes.io/version |
Текущая версия приложения (например, семантическая версия, хеш коммита и т.д.) | 5.7.21 |
string |
app.kubernetes.io/component |
Имя компонента в архитектуре | database |
string |
app.kubernetes.io/part-of |
Имя основного приложения, частью которого является текущий объект | wordpress |
string |
app.kubernetes.io/managed-by |
Инструмент управления приложением | helm |
string |
Для демонстрации этих меток, рассмотрим следующий объект StatefulSet:
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
app.kubernetes.io/managed-by: helm
Приложения и экземпляры приложений
Одно и то же приложение может быть установлено несколько раз в кластер Kubernetes, в ряде случаев — в одинаковое пространство имен. Например, WordPress может быть установлен более одного раза, тогда каждый из сайтов будет иметь собственный установленный экземпляр WordPress.
Имя приложения и имя экземпляра хранятся по отдельности. Например, WordPress имеет ключ app.kubernetes.io/name со значением wordpress, при этом у него есть имя экземпляра, представленное ключом app.kubernetes.io/instance со значением wordpress-abcxzy. Такой механизм позволяет идентифицировать как приложение, так и экземпляры приложения. У каждого экземпляра приложения должно быть уникальное имя.
Примеры
Следующие примеры показывают разные способы использования общих меток, поэтому они различаются по степени сложности.
Простой сервис без состояния
Допустим, у нас есть простой сервис без состояния, развернутый с помощью объектов Deployment и Service. Следующие два фрагмента конфигурации показывают, как можно использовать метки в самом простом варианте.
Объект Deployment используется для наблюдения за подами, на которых запущено приложение.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxzy
...
Объект Service используется для открытия доступа к приложению.
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxzy
...
Веб-приложение с базой данных
Рассмотрим случай немного посложнее: веб-приложение (WordPress), которое использует базу данных (MySQL), установленное с помощью Helm. В следующих фрагментов конфигурации объектов отображена отправная точка развертывания такого приложения.
Следующий объект Deployment используется для WordPress:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
Объект Service используется для открытия доступа к WordPress:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
MySQL открывается в виде StatefulSet с метаданными как для самого приложения, так и основного (родительского) приложения, к которому принадлежит СУБД:
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
...
Объект Service предоставляет MySQL в составе WordPress:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: mysql-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
...
Вы заметите, что StatefulSet и Service MySQL содержат больше информации о MySQL и WordPress.